AI/ML○Pass

Lanes now runs Claude Fable 5 across parallel agent sessions
Feature announcement blog post, not a new project for Show HN.
s-xyz
4025d ago
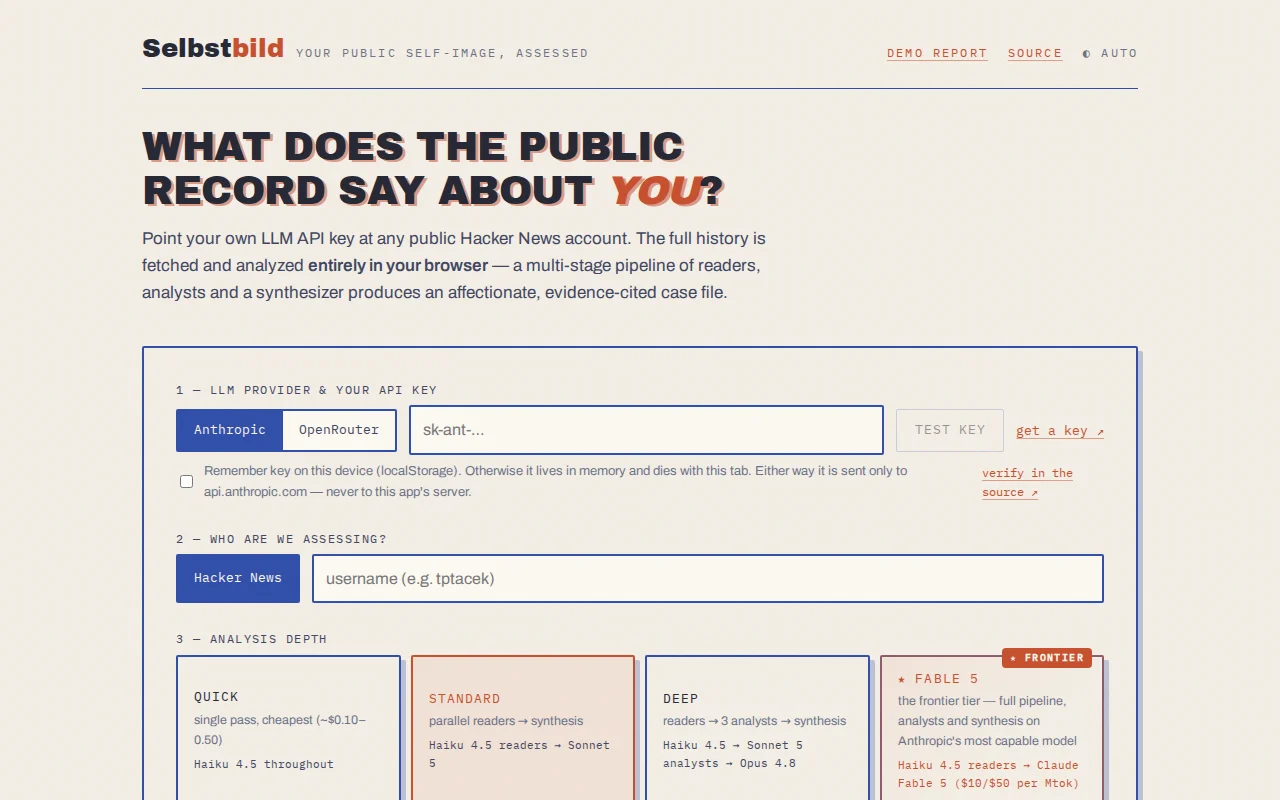
Having had my perfection confirmed, I decided to share this joy with you as I had a few percent usage left before a reset. I took a few prompts, then did a review of the output which resulted in Selbstbild, a BYOK (Anthropic / OpenRouter) web app that gives you a summary and assessment of your public comments by one of our machine Gods, including Fable 5 (provided your can afford that luxury at API pricing).
In all seriousness, I have, for a long time, used my own comments on social media (including HN) as part of a personal needle-in-haystack test, simply because I do know my somewhat peculiar style and what I tend to write, but also because I can sometimes write in a slightly confusing manner, making for a decently quick check during a models release window. Lately though, what with long context retrieval at the frontier having become rather robust, the interesting part has become not whether but how a model sifts through this unstructured collection of comments, what is surfaced in which manner, etc. Hence this.
* Everything runs in your browser, the only network calls go to Anthropic / OpenRouter and the platform APIs, nothing is proxied through a server, no analytics, no cookies. Feel free to verify via the network tab and source code, I would. * You get a cost estimate before any tokens are spent, so no surprises there. * Caveats: LLMs are not intelligent entities, have no predictive abilities and this is not a tool for professional assessment of your person. This is a horoscope for nerds. * Creation: Fable built essentially all of this itself, my own contribution was a few minutes of prompting, plus review and deployment. * No cookie banner: Turns out you aren’t actually “forced” to display one, just if you are doing something that, in my opinion, users should really be aware of you doing do you actually need one. * Classifier: Depending on your topic, your comments may trigger the Fable 5 classifier. Nothing I can do about this, but it’s transparently communicated. For what it’s worth, my comments did not trigger it.
On the state of LLM coding as a whole: My review found a few issues. Deleting from Cloudflare KV did not account for cache initially, so that could lead to content being retained even when users requested deletion, which isn’t ideal. Also, a few “any” snuck in and Fable 5 decided on an ancient version of the Anthropic API. Was caught via a quick read of the code, which is overall as pleasant to review as can be (certainly prefer reviewing Anthropic model output over GPT-5.5 purely from a subjective standpoint) but if such obvious deficiencies can sneak in on such a simple project with such an advanced model, that tells me we are still far from a stage where “no review” is even something we can discuss. These issues would have likely been caught by a second review pass anyways (whether using a review agent, prompting Fable or another model), but it still gives me pause what other issues could sneak in as part of more important and complex code bases.
Get yourself assessed by Fable 5: https://selbstbild.eu
Feature announcement blog post, not a new project for Show HN.
Prompt engineering library dressed up as metacognition infrastructure.
AI-generated Pac-Man clone when GitHub Copilot already writes game code.
AI-generated fables about PHP routing isn't a product, it's marketing content.
I'm building Guildly, a Slack-like interface where you can run a company of AI employees. I recently used Fable to revamp the whole website into a cool retro pi
Python port of Pts.js with visual composability as the core hypothesis.