Finance●Mid
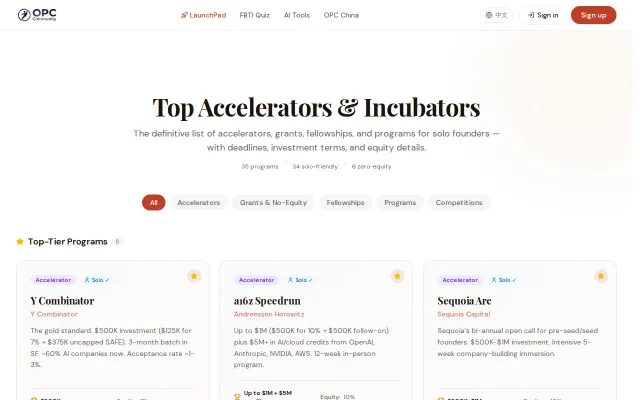
I compiled a list of solo-founder-friendly accelerators and grants
Filters 35 programs specifically for solo founders with zero-equity options.
Cozy
patrickliu007
301mo ago

They're putting real cash and infrastructure behind a problem the field keeps kicking down the road: evaluation for agentic systems. The program explicitly targets environment complexity, autonomy horizon, and output complexity, and ropes in sensible partners (Hugging Face, PyTorch, etc.) — that's a practical way to seed meaningful open benchmarks rather than another leaderboard. Missing: concrete application criteria, timeline, and license/reproducibility guarantees, which will determine whether this becomes useful research infrastructure or just noise.
AI/ML researchers, academic teams, open-source contributors, benchmark and dataset builders, evaluation-focused engineers
Our ability to measure AI has been outpaced by our ability to develop it, and we believe this evaluation gap is one of the most important problems in AI. Open benchmarks are one of the most important levers for advancing AI safely and responsibly—but the academic and open-source teams driving them often hit resource constraints, especially in the face of the exponentially expanding complexity of what tomorrow’s benchmarks need to cover.
We think the next wave of benchmarks needs to push on three axes: - Environment complexity - How realistic is the operating environment? - Autonomy horizon - How far can an agent operate independently? We need to measure - Output complexity - How sophisticated is the work product?
Happy to answer questions about the grants, the framework, and would love to hear more about what you’re building!
Filters 35 programs specifically for solo founders with zero-equity options.
This skill automates the tedious parts of writing program logic models — it outputs a 5-level results chain, an if/then Theory of Change with assumptions, SMART indicators, SDG mapping and a monitoring plan. That feature set is exactly what M&E teams and grant writers want, but the public face is rough (ClawHub shows "Skill not found"), so the project needs clearer example outputs, ready-to-copy indicator templates, and better onboarding to move from useful hobby to everyday tool.
Direct netlink manipulation beats fwknop complexity for single-packet authorization.
OAuth-equivalent for agents: cryptographic identity, scoped grants, audit trail.
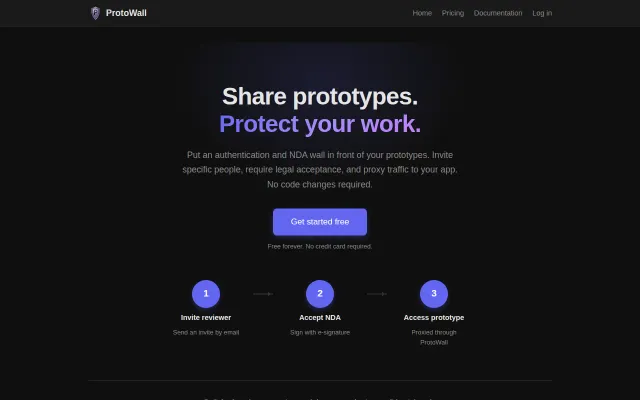
NDA signing before prototype access beats password-protected Vercel deployments.
Hierarchical KV store for AI memory, but Electric SQL and PowerSync already solve this.