Gaming●Mid
Vibe-coding video games with Claude (Day 30: Chess)
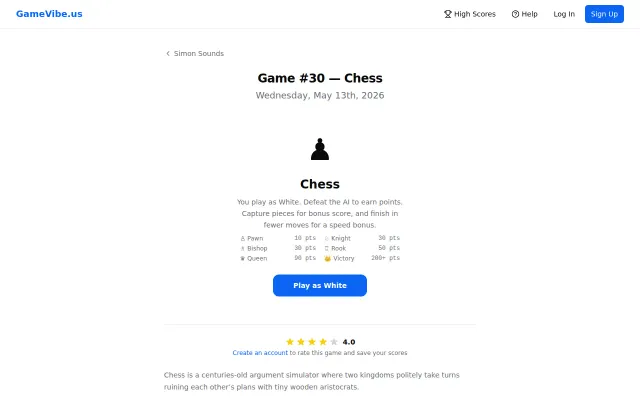
Yet another browser chess clone, but the AI is surprisingly decent.
Ship It
pzxc
101mo ago
The scoring model is the real clever bit: mixing semantic CLIP checks with a separate CLIP-based faithfulness test plus HSV and HOG-lite signals makes the feedback much harder to game than a single metric. The product wraps that into a tight, addictive loop—daily challenges, speed/unlimited modes and leaderboards—so it actually teaches you to write better prompts; just be aware it still inherits CLIP blind spots and could be optimized around the exact weighting scheme.
Prompt engineers, AI/ML enthusiasts, generative-art creators, and anyone practicing text-to-image prompting
Core mechanic: user sees a target image, writes a prompt, model generates output, and we score similarity.
Scoring uses multiple signals so one metric doesn’t dominate:
1. Semantic alignment (CLIP) - user_prompt -> target_image (is the prompt conceptually aligned with target?) - user_image -> target_image (is the generated result semantically aligned with target?)
2. Prompt faithfulness (CLIP) - user_prompt -> user_image (did generation actually follow the submitted prompt?)
3. Color similarity - HSV histogram overlap (user_image vs target_image) for palette/tone distribution
4. Structure similarity - HOG-lite gradient/orientation comparison (user_image vs target_image) for layout/edge composition
Final score is a weighted blend (content signals weighted highest), normalized to player-facing points.
Why this approach: - CLIP-only can overrate semantically related but visually off outputs - color-only ignores structure/meaning - structure-only misses semantics/style - combining prompt-image and image-image signals reduced obvious false positives in ranking
Stack: - Spring Boot backend - separate CLIP scoring container - external image generation service - Next.js frontend - PostgreSQL
Would love technical feedback on: - metric weighting/calibration - known failure modes I should benchmark - alternatives to HOG-lite for fast structural scoring
Yet another browser chess clone, but the AI is surprisingly decent.
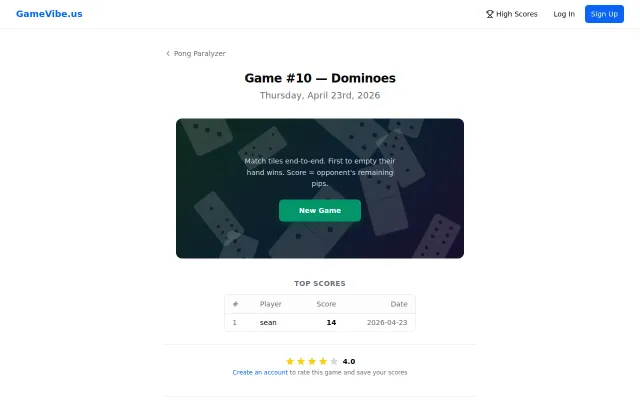
Day 10 of an AI coding challenge, but standard browser dominoes gameplay.
AI vision judging adds a funny twist to the standard Pictionary-style formula.
Neural net bots trained on human data finally make solo Tichu practice viable.
Idle game mechanics actually teach overfitting and compute tradeoffs correctly.
Deduping PRs and scoring them with 20 heuristic signals is a concrete, useful idea — especially the scope-coherence signal and embedding auto-fallback for providers without embeddings. The repo supports CLI, a persistent server, GitHub App integration and an explicit --model flag for provider flexibility, but it's still early and adoption/UX examples (ranked output, workflows) are thin — promising engineering scaffolding that needs real-world validation.