Developer Tools●●Solid
Bbt – Black Box Testing Directly from Your Documentation
Tests live in README as plain English; clever partial parsing eliminates Gherkin boilerplate overhead.
Big BrainNiche Gem
LionelDraghi
303mo ago

Blog post about someone else's code; not a standalone project.
AI researchers, machine learning students, technical product managers
The Architecture of Simplicity Unlike modern frameworks that hide complexity behind optimized CUDA kernels, microgpt exposes the raw mathematical machinery. The code implements:
The Autograd Engine: A custom Value class that handles the recursive chain rule for backpropagation without any external libraries.
GPT-2 Primitives: Atomic implementations of RMSNorm, Multi-head Attention, and MLP blocks, following the GPT-2 lineage with modernizations like ReLU.
The Adam Optimizer: A pure Python version of the Adam optimizer, proving that the "magic" of training is just well-orchestrated calculus.
The Shift to the Edge: Privacy, Latency, and Power For my doctoral research at Woxsen University, this codebase serves as a blueprint for the future of Edge AI. As we move away from centralized, massive server farms, the ability to run "atomic" LLMs directly on hardware is becoming a strategic necessity. Karpathy's implementation provides empirical clarity on how we can incorporate on-device MicroGPTs to solve three critical industry challenges:
Better Latency: By eliminating the round-trip to the cloud, on-device models enable real-time inference. Understanding these 243 lines allows researchers to optimize the "atomic" core specifically for edge hardware constraints.
Data Protection & Privacy: In a world where data is the new currency, processing information locally on the user's device ensures that sensitive inputs never leave the personal ecosystem, fundamentally aligning with modern data sovereignty standards.
Mastering the Primitives: For Technical Product Managers, this project proves that "intelligence" doesn't require a dependency-heavy stack. We can now envision lightweight, specialized agents that are fast, private, and highly efficient.
Karpathy’s work reminds us that to build the next generation of private, edge-native AI products, we must first master the fundamentals that fit on a single screen of code. The future is moving toward decentralized, on-device intelligence built on these very primitives. Link:
Tests live in README as plain English; clever partial parsing eliminates Gherkin boilerplate overhead.
Type a name and you can literally watch characters turn into IDs, 16‑dim embeddings get added with positional encodings, and causal attention matrices animate per head — all matched numerically to Karpathy's 244‑line microGPT. The implementation is pure TypeScript (no ML libs) and includes a helpful scrollable sidebar with the reference math, which makes this an excellent, low‑friction learning tool — more pedagogical deep dive than research innovation.
Train a working LLM in 5 minutes on free Colab with a fish personality.
Detects sycophancy and jailbreak drift in LLMs without needing model weights.
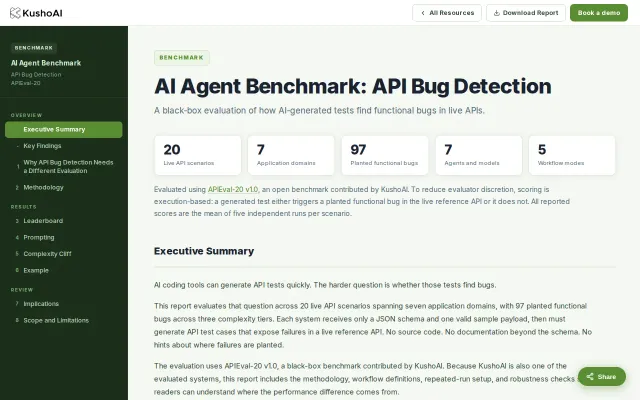
Execution-based scoring with live APIs beats LLM-graded benchmarks, but they evaluated themselves.
Cryptographic audit chain for agents, but lacks observability dashboards competing tools provide.