Developer Tools●Mid
Vibe Coding Review Checklist – Evaluate AI-Generated Code Quality
Comprehensive checklist, but CLAUDE.md and cursor rules already solve this locally.
Solve My Problem
LetsAutomate
103mo ago
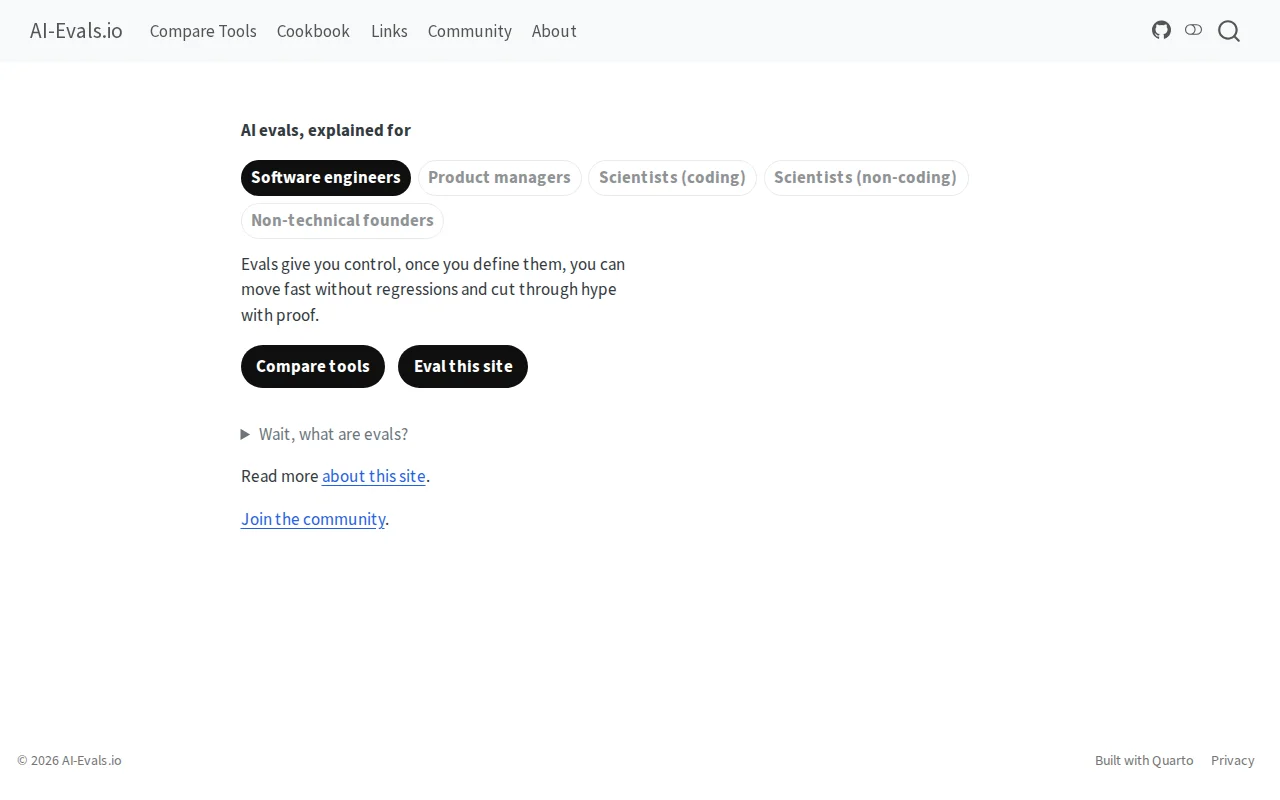
LLM evaluation guide eats its own dogfood with eval-based site design.
Software engineers, product managers, and non-technical teams integrating AI into workflows
Evidently AI · Ragas · BrainTrust
That one-liner is aimed at software engineers, but I've spent my career helping cross-functional teams collaborate, and that's really what this is about. AI agents make powerful workflows very plausible, but only if teams can grow them incrementally without losing control - no vendor lock-in, no discipline silos, no blind trust in outputs.
The site tries to meet different audiences where they are, with mostly practice over theory: tool comparisons, minimal approaches, and freedom to work at whatever level of complexity serves you - whether that's Claude Code with Agent Skills, local models, or custom Python agents.
As a fun "eat your own dog food" experiment, I use the site itself as the reproducible cookbook ("eval-ception") [2]. It's the quickest way to feel what different eval tools are actually like in practice.
I welcome feedback, contributions, or stories. More on the project and what's coming [3]. It's a rewarding area once you realize you can keep control and move methodically - doesn't matter if it's the smallest model or a swarm.
Comprehensive checklist, but CLAUDE.md and cursor rules already solve this locally.
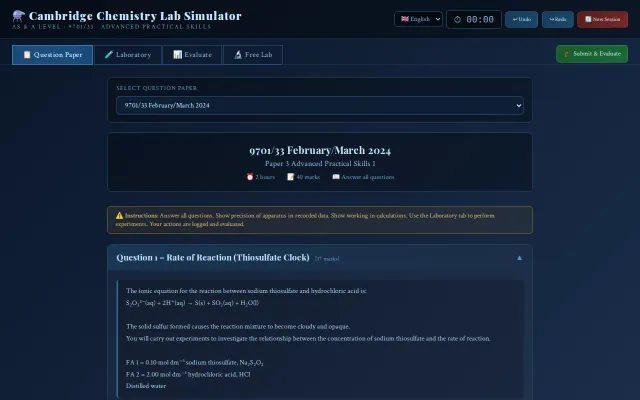
Replaces expensive lab equipment with exam-accurate simulation, logging precision and calculations.
Claude Skill for agent evals, but LangSmith and Arize already own this.
Terminal-native prompt evals with diff proposals beats web dashboards.
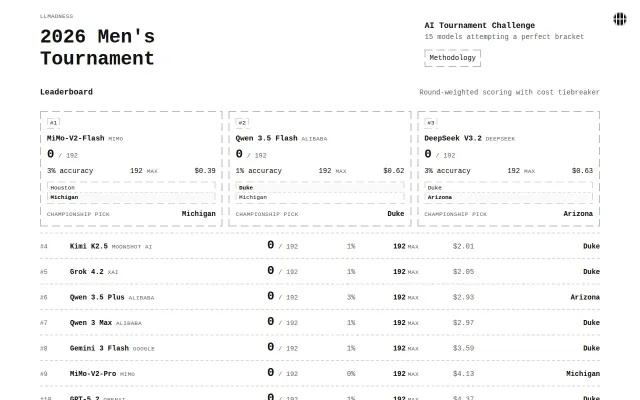
Claude Opus spent $59.55 versus MiMo-Flash at $0.39 for identical bracket predictions.
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.