AI/ML●●Solid
We beat Gemini Embedding 2 by training only 16M params (open weights)
16M trained params beats Gemini Embedding 2 on audio-text retrieval.
Big BrainNiche Gem
abtonmoy
7011d ago
Hybrid AI system with Production Assistant and Self-Learning Core using Engram Graph Memory (NetworkX)
The repo openly rejects the 'frozen weights' assumption and tries to prototype an assistant that rewires online — you can see the scaffolding in files like autonomous_ai.py, view_graph.py, a configs folder, a streamlit_apps dir and chroma_data. That's an interesting, contrarian direction, but the project is clearly early-stage: the UI and repo layout are tidy, yet there’s little in-repo evidence of benchmarks, experiments, or reproducible results to back the big claim.
AI/ML researchers, hobbyist machine-learning engineers, and experimental developers interested in continual learning and AGI alternatives
16M trained params beats Gemini Embedding 2 on audio-text retrieval.
Frozen 12B model hits 93.3% AIME by grafting verified KV states, not retraining.
Zero-initialized overlay changes model beliefs without touching a single base weight.
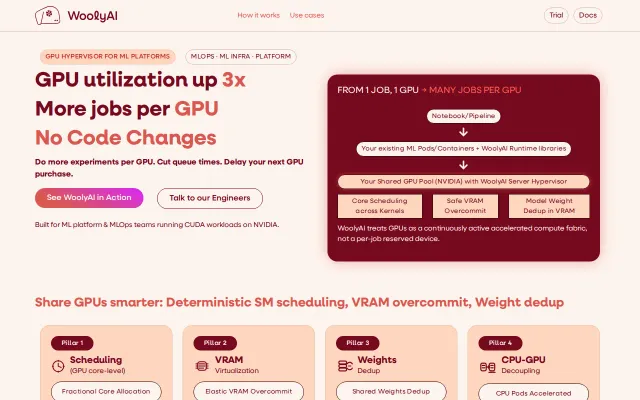
LoRA weight dedup is clever, but Run:AI and NVIDIA MIG already own GPU virtualization.
Deterministic fingerprinting for model structure without loading weights.
Home rig for attribute-weighted benchmarking lacks the polish of established eval frameworks.