Infrastructure●●Solid
Hanoi-CLI – simulate and optimize pod placement in Kubernetes
Read-only rebalance advisor with constraint-aware planning beats manual kubectl debugging.
Niche GemBig Brain
kreicer
202mo ago
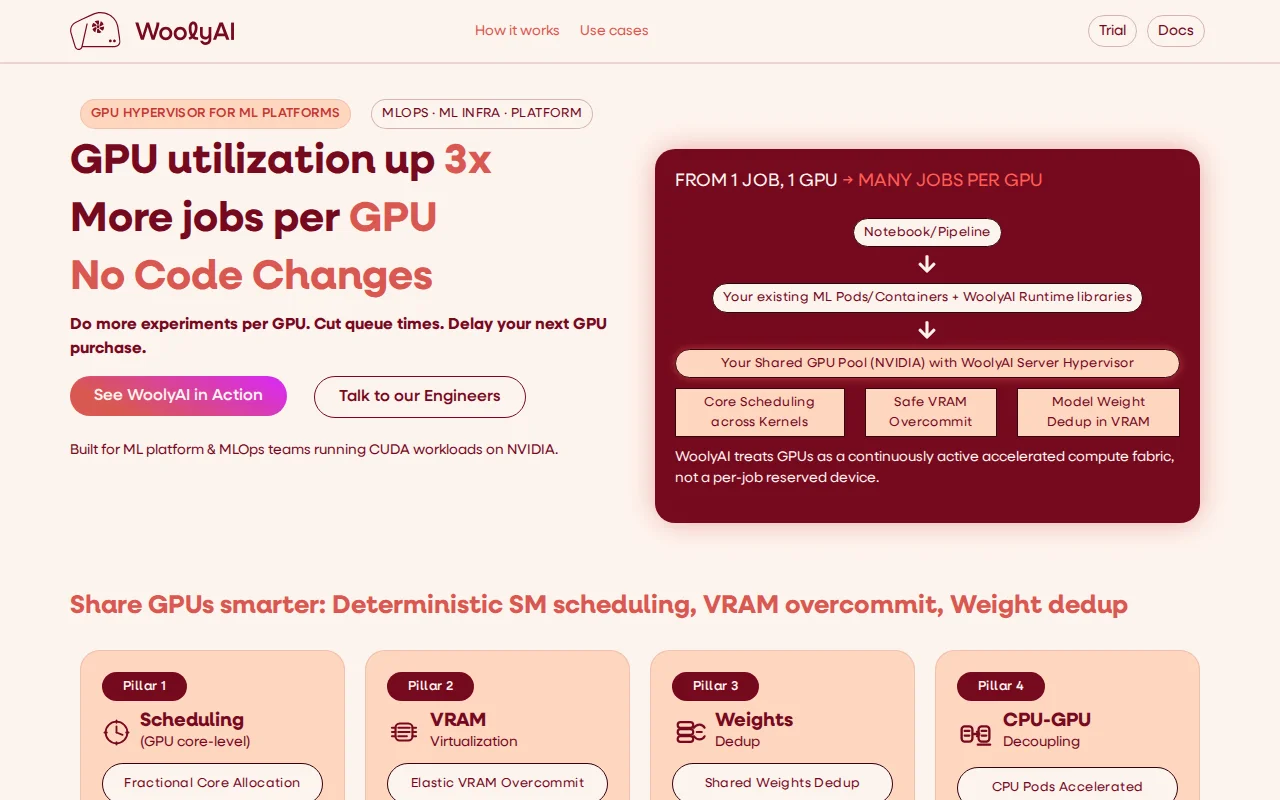
LoRA weight dedup is clever, but Run:AI and NVIDIA MIG already own GPU virtualization.
ML platform teams and MLOps engineers running CUDA workloads on NVIDIA
Run:AI · NVIDIA MIG · CoreWeave
We are looking for teams to give it a try.
More details to get a trial license - https://www.woolyai.com.
Read-only rebalance advisor with constraint-aware planning beats manual kubectl debugging.
Reveals agents diagnose bottlenecks 87% correctly but fix them only 17%—scaffolding matters more than model.
Actually tells you why your GPU is slow instead of just showing 100% utilization like nvidia-smi.
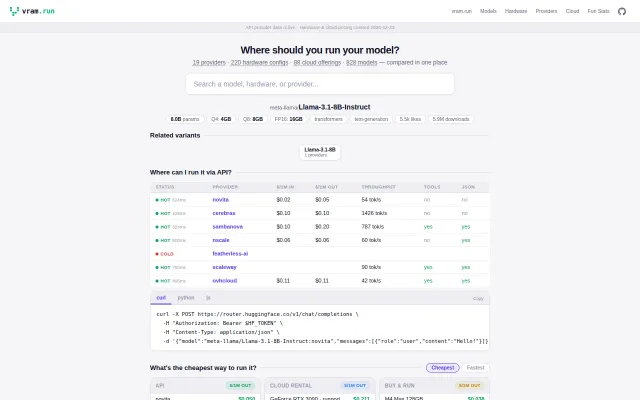
Single lookup table: cheapest way to run any model across APIs, GPUs, or cloud.
Agentic RAG with self-evaluator loop, but evaluator/generator sharing one model due to VRAM constraints.
Agentic RAG with self-evaluator loop, but evaluator/generator sharing one model due to VRAM constraints.