AI/ML●Mid
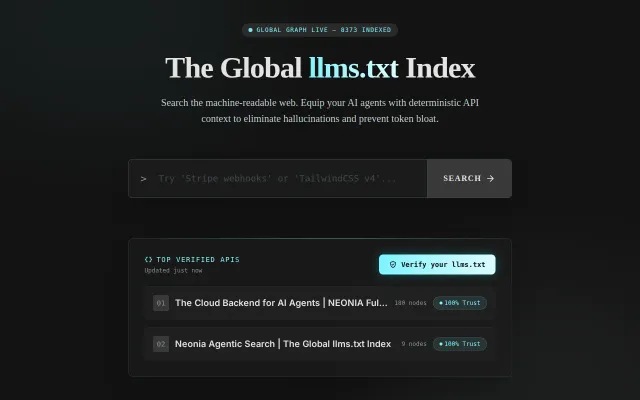
The Global Llms.txt Index
Searchable directory for llms.txt files when general search engines could index these.
Ship It
olex-green
2013d ago
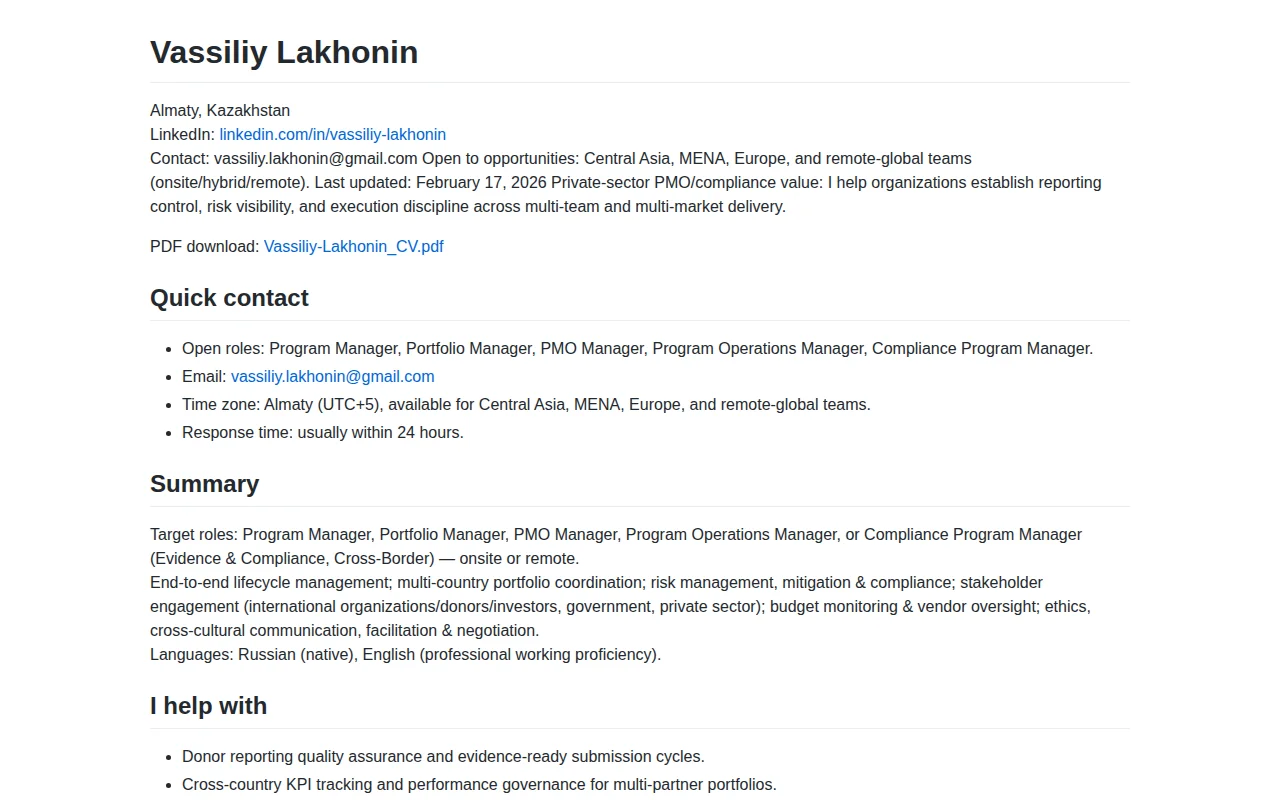
Includes actual machine-readable artifacts (resume.json, evidence.json, llms.txt, agent-card.json) plus JSON-LD and GitHub Actions for basic indexing — that's an honest, useful handshake between a human CV and automated agents. Smart idea and practical execution, but it stops short of delivering searchable semantics or an embedded search UI so the structured data mostly benefits bots rather than helping humans scan in 60 seconds.
Recruiters, hiring managers, hiring AI/agents, non-technical professionals who want an LLM-friendly CV
I tried to make it useful for both recruiters and AI tools: -Clear one-page profile + downloadable PDF -Case studies with concrete results -Work samples -Structured files for discovery and parsing (llms.txt, resume.json, evidence.json, availability.json, agent-card.json, engage.json) -Basic indexing and quality checks (sitemap, robots, JSON-LD, GitHub Actions)
Main idea: less friction to evaluate fit, verify claims, and contact me fast.
Would love feedback from HN: If you scanned this in 60 seconds, what would you improve first?
Website: https://vassiliylakhonin.github.io/ Source: https://github.com/vassiliylakhonin/vassiliylakhonin.github....
Searchable directory for llms.txt files when general search engines could index these.
This is someone treating a CV as structured data rather than a PDF: resume.json, evidence.json, availability.json, agent-card.json and a curated llms.txt are all exposed plus schema.org JSON-LD. Nice touches include GitHub Actions that validate links and push an IndexNow update on every commit — practical engineering to get content noticed by crawlers and agents. It’s a focused, well-implemented experiment, but its usefulness depends on broader adoption or tooling that consumes these bespoke conventions.
Nine AI-generated rooms exploring machine perception using OpenAI Codex.
Orchestrates two AI tools you already pay for; requires both Codex and Claude.
PDF/A-3 embedding solves JSON Resume's adoption problem elegantly.
Keeps long-running Codex agents synchronized across machines via Git-controlled profiles.