Developer Tools●●●Banger
Quicktok, an exact BPE tokenizer 7x faster than tiktoken
Zero-dependency C++20 tokenizer hitting 92 MB/s while matching tiktoken output byte-for-byte.
WizardryBig Brain
dmatth1
3116d ago
GreedyPhrase Tokenizer: Maximizing Effective Context via Greedy Phrase Compression
Phrase-mining beats tiktoken compression 1.21x with 1/3 vocab size, but niche for token optimization.
LLM builders optimizing context windows and inference throughput
Tiktoken · SentencePiece · BPE tokenizers
Benchmark (enwik9, 1 GB):
Tokenizer Vocab Size Total Tokens Ratio Throughput GreedyPhrase 65,536 222,805,405 4.49x 47 MB/s Tiktoken o200k_base (GPT-4o) 200,019 270,616,861 3.70x 4.35 MB/s Tiktoken cl100k_base (GPT-4) 100,277 273,662,103 3.65x 7.13 MB/s
GreedyPhrase: 1.23x better than GPT-4, 1.21x better than GPT-4o. 1.5-3x smaller vocab, 6-11x higher encoding throughput.
How It Works:
1. Phrase Mining — Split into atoms (words, punctuation, whitespace). Mine bigrams/trigrams. Top phrases fill 95% vocab slots.
2. BPE Fallback — Train BPE on residual byte sequences. Fills remaining 5% vocab.
3. Greedy Encoding — Longest-match-first Trie. Byte fallback for unknowns (zero OOV).
Zero-dependency C++20 tokenizer hitting 92 MB/s while matching tiktoken output byte-for-byte.
21x KV-cache restore speedup sounds huge, but the Medium link returns a 500 error.
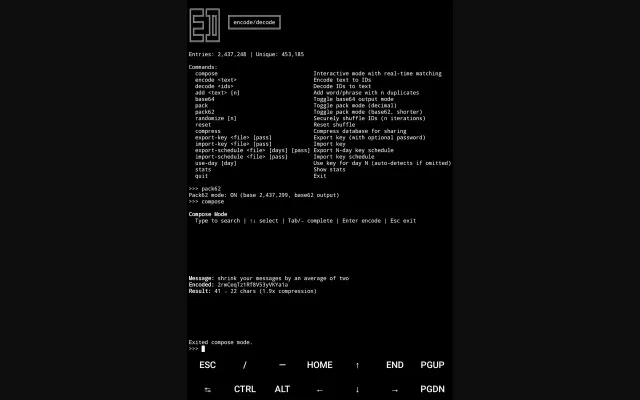
450k-entry codebook compresses text by 61% using phrase substitution.
Nine times faster than tiktoken-rs with swappable lexer backends for benchmarking.
Native binary format beats JSONEachRow by 2–8x on large payloads with ZSTD compression.
Pure C99 GPT with SIMD beats Python 4,600x; drop two files into any project.