AI/ML●●●Banger
MicroGPT-C – C99 GPT for Edge Training and Tiny Model Pipelines
Karpathy's microgpt in C99, proves tiny coordinated models beat single large models on logic.
WizardryBig Brain
Ajay__soni
103mo ago
Zero-dependency C99 GPT-2 engine for edge AI. Sub-1M parameter models train on-device in seconds. Organelle Pipeline Architecture (OPA) coordinates specialised micro-models — 91% win rates on 11 logic games with 30K–160K parameters. Composition beats capacity.
Pure C99 GPT with SIMD beats Python 4,600x; drop two files into any project.
Systems engineers, embedded developers, ML researchers exploring low-level optimization
Karpathy's microgpt.py · llama.c · tinygrad
The Punchline: I made it go 4,600x faster in pure C code, no dependencies and using a compiler with SIMD auto-vectorisation!!!
Andrej recently released microgpt.py - a brilliant, atomic look at the core of a GPT. As a low-latency developer, I couldn't resist seeing how fast it could go when you get closer to the metal.
So just for funzies, I spent a few hours building microgpt-c, a zero-dependency and pure C99 implementation featuring:
- 4,600x Faster training vs the Python reference (Tested on MacBook Pro M2 Max). On Windows, it is 2,300x faster. - SIMD Auto-vectorisation for high-speed matrix operations. - INT8 Quantisation (reducing weight storage by ~8x). Training is slightly slower, but the storage reduction is significant.
- Zero Dependencies - just pure logic.
The amalgamation image below is just for fun (and to show off the density!), but the GitHub repo contains the fully commented, structured code for anyone who wants to play with on-device AI.
I have started to build something useful, like a simple C code static analyser - I will do a follow-up post.
Everything else is just efficiency... but efficiency is where the magic happens
Karpathy's microgpt in C99, proves tiny coordinated models beat single large models on logic.
Blog post about someone else's code; not a standalone project.
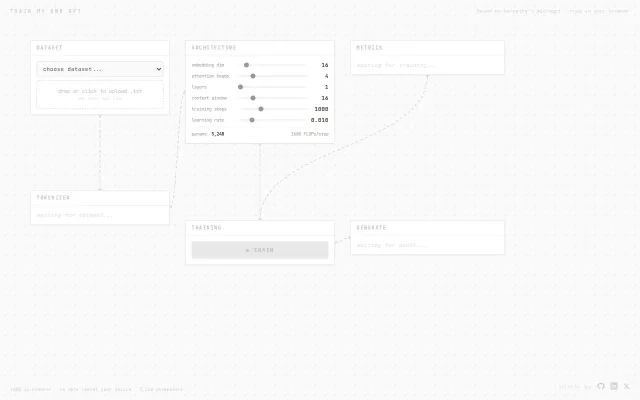
Karpathy's microGPT in the browser with live loss curves, but pedagogical only—no production value.
Karpathy's minigpt ported to TS, readable code instead of brevity Olympics.
600x speedup over Node.js version, but Cursor support is currently broken.
Type a name and you can literally watch characters turn into IDs, 16‑dim embeddings get added with positional encodings, and causal attention matrices animate per head — all matched numerically to Karpathy's 244‑line microGPT. The implementation is pure TypeScript (no ML libs) and includes a helpful scrollable sidebar with the reference math, which makes this an excellent, low‑friction learning tool — more pedagogical deep dive than research innovation.