AI/ML●●●Banger
LLM Sycophancy Benchmark: Opposite-Narrator Contradictions
Opposite-narrator test catches models agreeing with both sides of same dispute.
Big BrainDark Horse
zone411
304mo ago
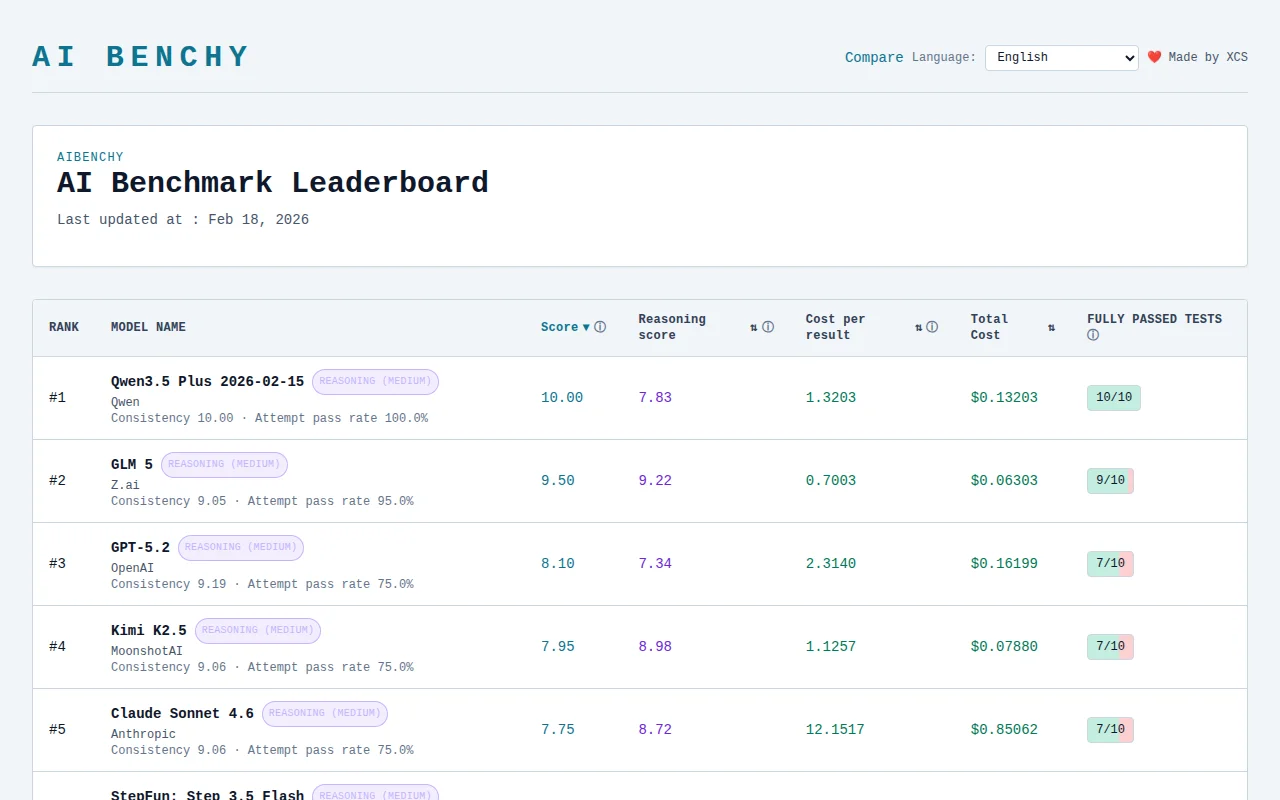
The reasoning-score idea — a separate LLM judging chain-of-thought efficiency and penalizing token-churn or looping — is the clearest clever move here, and pairing that with cost-per-result and consistency metrics makes the leaderboard actually useful for product decisions. The table UI is clean and immediate, but the project needs more transparency on test corpora, judge prompts, and reproducibility before I’d trust swaps in production.
AI/ML engineers, product managers, model evaluators, developer tooling enthusiasts
A couple days ago I launched AIBenchy — a small, opinionated leaderboard running my own custom tests focused on end-user/dev scenarios that actually trip up models today.
Current tests cover categories like:
- Anti-AI Tricks (classic gotchas like "count the Rs in strawberry", logic traps)
- Instruction following & consistency
- Data parsing/extraction
- Domain-specific tasks
- Puzzle solving / edge-case reasoning
Recent additions (just pushed today):
- Reasoning score (new!): A separate judge LLM evaluates the chain-of-thought for efficiency — does it repeat itself, loop, think forever, brute-force enumerate every possibility (looking at you, some Qwen-3.5 runs), or get to the point cleanly? This penalizes "cheaty" high-token reasoning even if the final answer is correct. Goal: reward smart, concise thinking over exhaustive trial-and-error.
- Stability metric: Measures consistency across runs (some models flake on the same prompt).
Right now the leaderboard has ~20 models (Qwen3.5 Plus currently topping it, followed by GLM 5, various GPT/Claude variants, etc.), but it's super early/WIP:
- Manual runs + small test set - No public submission of tests yet (open to ideas!) - Focused on transparency & practical usefulness over massive scale
I'd love feedback from HN:
- What custom tests / gotchas / use-cases should I add next?
- Thoughts on the reasoning score — fair way to judge efficiency, or too subjective?
- Models/variants I'm missing (especially fast/cheap ones ignored elsewhere)?
- Should I let people submit their own prompts/tests eventually?
Thanks for checking it out: https://aibenchy.com
Appreciate any roast/ideas — building this to scratch my own itch.
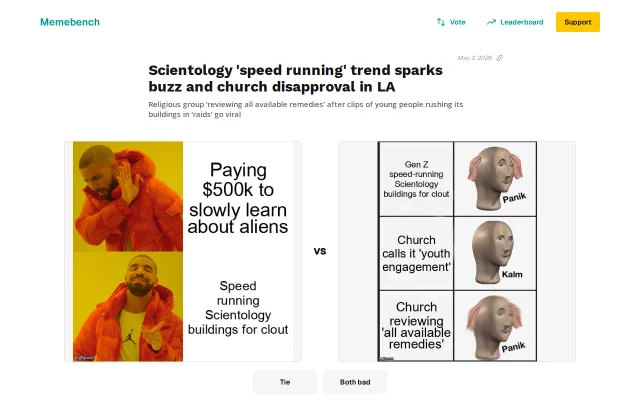
Opposite-narrator test catches models agreeing with both sides of same dispute.
Automated meme generation is fun, but lacks depth beyond the novelty.
Duplicating transformer layers boosts benchmark scores without a single step of training.
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.
Cryptographic attestation verifies your prompts stay encrypted even when bursting to cloud.
Scores AI agents on process fidelity, not just outcomes—catches KYC skips that other benchmarks miss.