AI/ML●●Solid
ErrataBench - A Proofreading Benchmark for LLMs
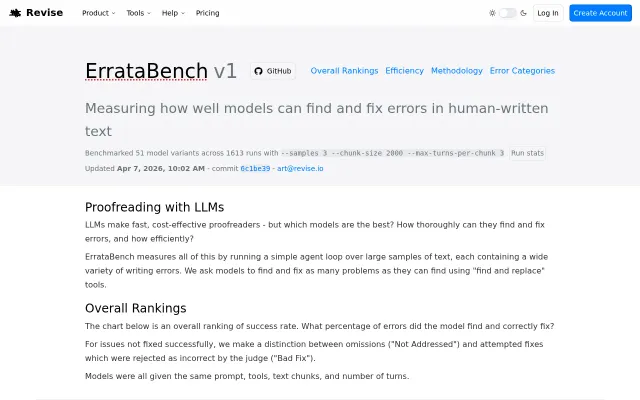
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.
Niche GemBig Brain
artursapek
301mo ago
LLM benchmark and leaderboard for narrator-bias sycophancy, opposite-narrator contradictions, and judgment consistency.
Opposite-narrator test catches models agreeing with both sides of same dispute.
AI researchers and ML engineers
HELM · BigBench · LMSys Arena
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.
First linter + benchmark for MCP servers; catches vague schemas before LLMs pick wrong tools.
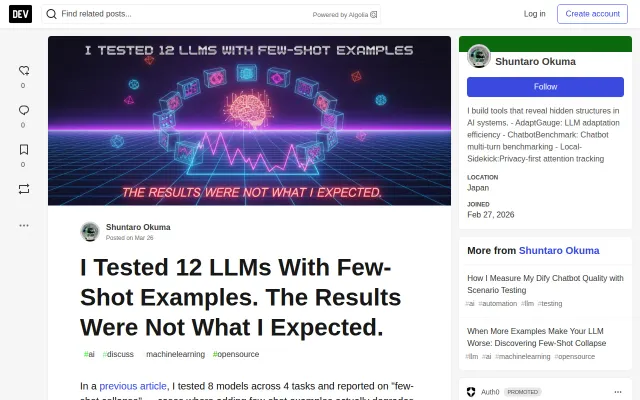
Research article revealing few-shot collapse patterns, not a usable tool or product.
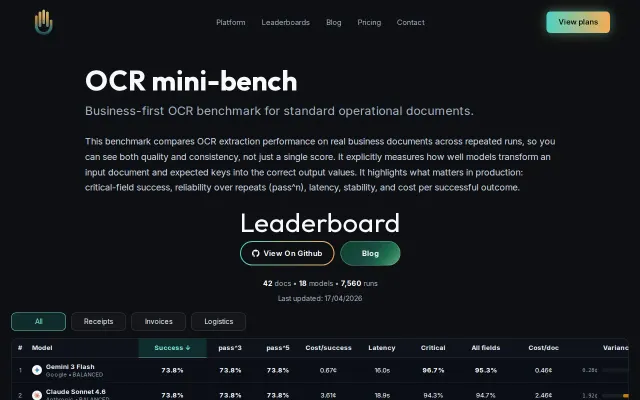
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
RFC 3339 hits 88% accuracy while unix epoch fails 50% of the time.