Health●Mid
Adentris (YC P25) – Find mistakes in your medical records
YC-backed SaaS doing AI medical compliance when dozens of enterprise tools already exist.
SlickSolve My Problem
digitaltzar
1642mo ago
Synthetic medical record generator with realistic schema variance across locales
This isn't another clean, English-only faker — it intentionally models script-specific OCR errors (Hebrew/Arabic/Latin confusions), per-hospital schema variance, and country-specific ID formats so models see the sort of mess real systems do. Output is NDJSON and usable from the CLI, which makes it straightforward to plug into pipelines, but the repo looks very new and documentation/examples are thin — promising concept, you’ll still need to tinker to use it at scale.
ML researchers, data scientists, and engineers working on healthcare NLP/OCR models or anyone who needs messy, multilingual synthetic medical records for training and evaluation
YC-backed SaaS doing AI medical compliance when dozens of enterprise tools already exist.
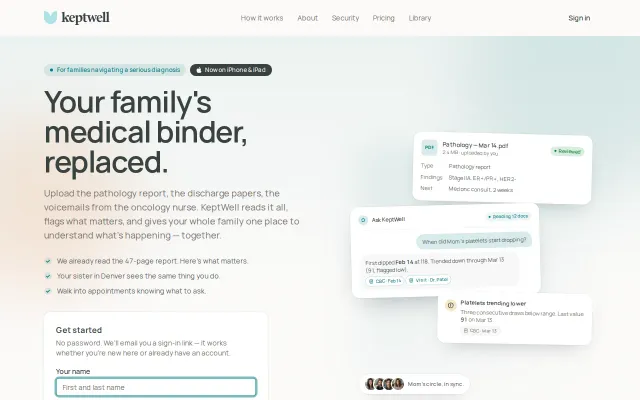
Family medical hub that extracts lab values and preps appointment questions.
CLI + MCP for openEHR workflows; solves real automation pain in healthcare, tiny but validated audience.
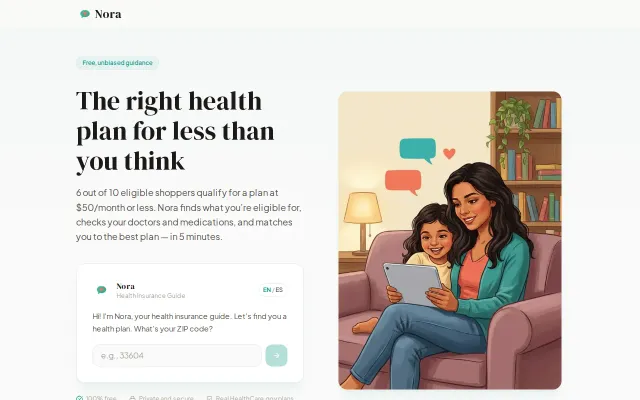
Chatbot for HealthCare.gov plans that actually checks your doctors and meds.
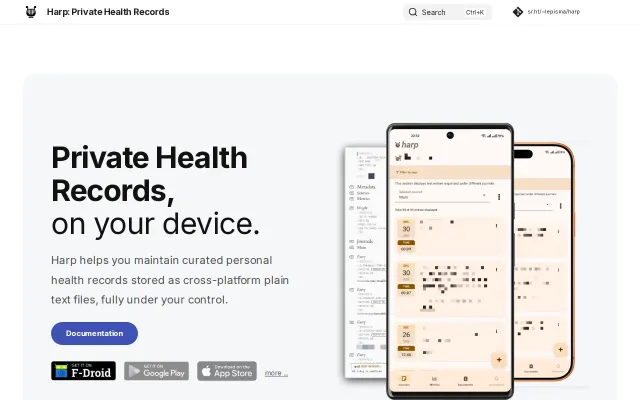
Org Mode health records with offline-first design and file ownership.
23 legal prompts, but remove.bg and 10k form-filling tools already solve this.