AI/ML●●Solid
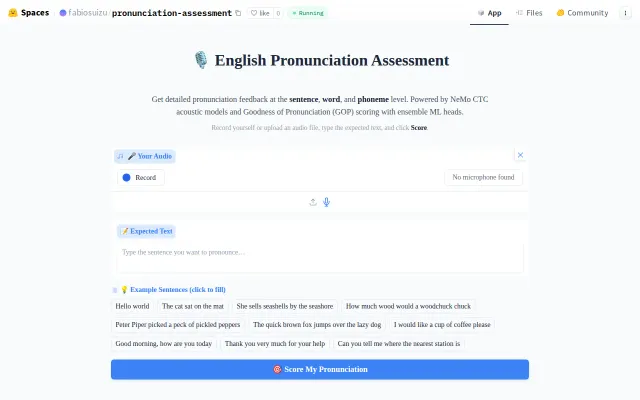
17MB pronunciation scorer beats human experts at phoneme accuracy
Phoneme-level scoring under 17MB beats commercial tools, but unclear if it generalizes beyond English.
Niche GemSolve My Problem
fabiosuizu
105mo ago
Beats human experts at phoneme scoring while 70x smaller than SOTA models.
Language learning app developers, speech-enabled education platforms, ESL instructors
Google Cloud Speech-to-Text (pronunciation confidence scoring) · Speechocean762 reference systems (wav2vec2-based) · Azure Speech Service (pronunciation assessment)
Architecture: CTC forced alignment + GOP scoring + ensemble heads (MLP + XGBoost). No wav2vec2 or large self-supervised models — the entire pipeline uses a quantized NeMo Citrinet-256 as the acoustic backbone.
Benchmarked on speechocean762 (standard academic benchmark, 2500 utterances): - Phone accuracy (PCC): 0.580 — exceeds human inter-annotator agreement (0.555) - Sentence accuracy: 0.710 — exceeds human agreement (0.675) - Model is 70x smaller than wav2vec2-based SOTA
Trade-off: we're ~10-15% below SOTA on raw accuracy. But for real-time feedback in language learning apps, the latency/size trade-off is worth it.
Available as REST API, MCP server (for AI agents), and on Azure Marketplace.
Demo: https://huggingface.co/spaces/fabiosuizu/pronunciation-asses...
Interested in feedback on the scoring approach and use cases people would find valuable.
Phoneme-level scoring under 17MB beats commercial tools, but unclear if it generalizes beyond English.
Beats humans at pronunciation scoring but doesn't ship product integration yet.
We built a platform where you can ask all your "stupid" math questions, and you can upload all your lecture notes, and the way you do math. It then learns your
One-word Turing Test game, but lacks depth beyond the novelty of the mechanic itself.
Measures epistemic humility and paradox tolerance using AI-evaluated scenario responses.
Title says code generation, screenshot shows Azure cost tool — something's wrong here.