Education●Mid
Llama.cpp Tutorial 2026: Run GGUF Models Locally on CPU and GPU
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
Niche Gem
anju-kushwaha
1341mo ago
High-efficiency LLM inference engine in C++/CUDA. Run Llama 70B on RTX 3090.
33x speedup over mmap for 70B on RTX 3090, but still 0.2 tok/s vs vLLM's 30+ tok/s.
ML engineers optimizing inference on resource-constrained hardware, retro-gaming modders
vLLM · llama.cpp · NVIDIA TensorRT
This is the result of that question itself and some weekend vibecoding (it has the linked library repository in the readme as well), it seems to work, even on consumer gpus, it should work better on professional ones tho
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
Single CUDA dispatch beats M5 Max efficiency on a 2020 GPU — llama.cpp extracts 40% of available performance.
Pure math beats silicon: full LLM inference via auditable WASM+SIMD, zero compiler toolchain.
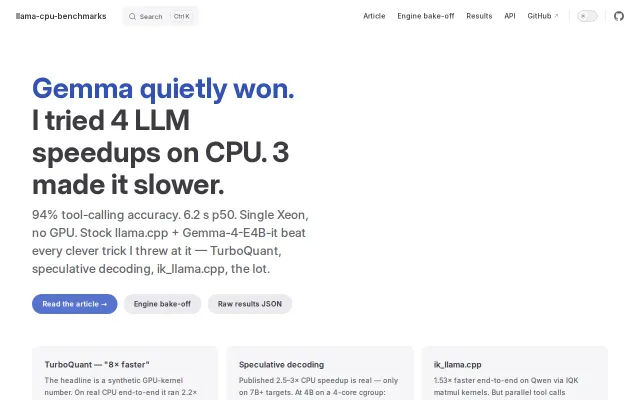
Proves speculative decoding slows down 4B models on 4-core CPUs despite marketing claims.
2x prefill speedup on 12k+ token contexts by treating GPUs like a production line.
Metal GPU stress testing in terminal, but is the workload realistic for benchmarking?