Education●Mid
Llama.cpp Tutorial 2026: Run GGUF Models Locally on CPU and GPU
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
Niche Gem
anju-kushwaha
1343mo ago
Stresses your CPU and Metal GPU from the terminal. Live utilization bars. macOS native.
Metal GPU stress testing in terminal, but is the workload realistic for benchmarking?
macOS developers and CI/CD pipelines needing GPU benchmarks without GUI
s-tui · stress-ng · Geekbench GPU
It runs matrix ops, FFTs, and particle sims concurrently and draws live utilization bars in the terminal — one for CPU, one for GPU.
Curious if the workload mix is actually representative or if I'm missing something obvious. Also open to feedback on the Metal implementation if anyone's gone down that path.
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
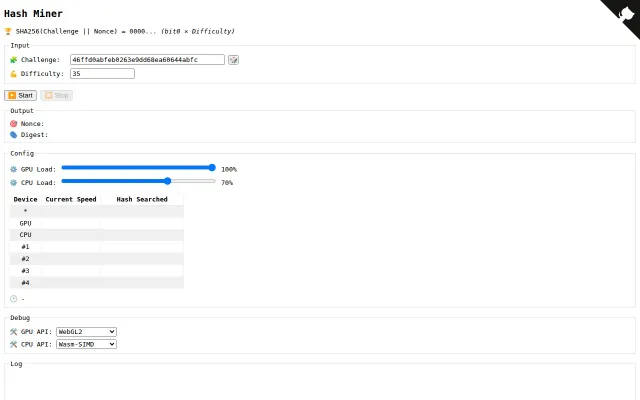
WebGPU and WASM-SIMD hash mining in browser with per-device load controls.
Saves neoclouds months of engineering by turning bare metal racks into managed Kubernetes clusters.
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.
Metal rendering is nice, but Neovide already does GPU acceleration cross-platform.
33x speedup over mmap for 70B on RTX 3090, but still 0.2 tok/s vs vLLM's 30+ tok/s.