AI/ML●●●Banger
Andrej Karpathy's microgpt.py to C99 microgpt.c – 4,600x faster
Pure C99 GPT with SIMD beats Python 4,600x; drop two files into any project.
WizardryZero to One
Ajay__soni
4035mo ago
Zero-dependency C99 GPT-2 engine for edge AI. Sub-1M parameter models train on-device in seconds. Organelle Pipeline Architecture (OPA) coordinates specialised micro-models — 91% win rates on 11 logic games with 30K–160K parameters. Composition beats capacity.
Karpathy's microgpt in C99, proves tiny coordinated models beat single large models on logic.
C/C++ systems engineers, edge AI researchers, low-latency embedded ML specialists
Karpathy's nanoGPT · llm.c
I’m a C/C++ architect focused on low-latency systems. Last year I tried building agentic pipelines with SLMs/LLMs and hit the usual wall: latency and orchestration overhead killed real-time edge use cases.
Initial research video: https://www.youtube.com/watch?v=q-rs9VZ1-0I
So I asked: how far can you push specialised logic at <1M parameters with nothing but local CPU?
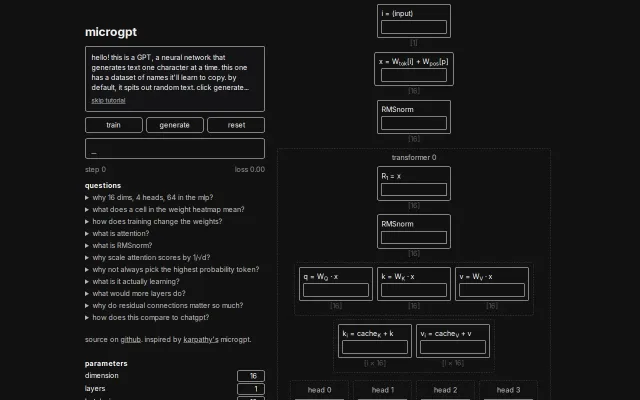
MicroGPT-C is a from-scratch C99 port of Karpathy’s microgpt.py[](https://gist.github.com/karpathy/8627fe009c40f57531cb1836010...). Zero deps, single-header, localised KV cache. Speed was never the goal (Andrej’s nanoGPT and llm.c already showed what’s possible). The real experiment was orchestration.
Organelle Pipeline Architecture (OPA): Agile-style Planners, Workers and Judges talking through tiny structured strings (board=XO_|valid=1,3) parsed by a safety-gated stack VM (3.7–5.8 M ops/s). A 64 K model needed 181 manual interventions; a 460 K model trained on those traces internalised everything and needed zero.
Beyond the research: fully auditable AI, great for education (~3 k lines of readable C), rapid prototyping, and embedded.
Personal itch: fraud/risk engines. I want agents that hunt “unknown-unknowns” in a sandbox where every decision is inspectable.
Happy to talk implementation, the 97 tests, 22 benchmarks, or anything else. FAQ: https://github.com/enjector/microgpt-c/blob/main/FAQ.md
Quick try (macOS/Linux/Windows): git clone https://github.com/enjector/microgpt-c && cd microgpt-c mkdir build && cd build && cmake .. -DCMAKE_BUILD_TYPE=Release && cmake --build . ./connect4_demo # 460 K params, ~21 min train, 88 % win rate vs random
Performance (Apple M2 Max): • 4.2 K params names: 685 k tok/s train, 110 k tok/s infer • 841 K Shakespeare char: 28 k / 16 k tok/s • 510 K Shakespeare word: 12.5 k / 40 k tok/s
Full leaderboard (11 games), market-regime experiment (57 % holdout = 2.8× baseline), and the book PDF: https://github.com/enjector/microgpt-c/blob/main/docs/book/M... GitHub: https://github.com/enjector/microgpt-c
Pure C99 GPT with SIMD beats Python 4,600x; drop two files into any project.
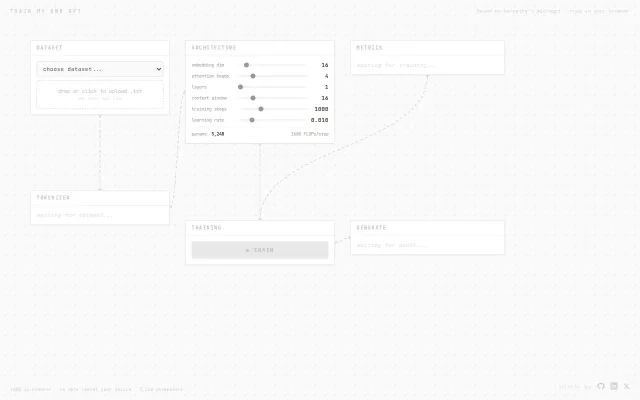
Karpathy's microGPT in the browser with live loss curves, but pedagogical only—no production value.
Visualize a 4K-param GPT learning in real-time with clickable layer explanations.
TPU training wrapper built on torchprime; solves a real problem but torchprime already exists.
Tiny footprint (~500 lines vs 400k OpenClaw), but local AI assistants are crowded.
Landing page with pricing but no code, demo, or technical details to evaluate.