AI/ML●Mid
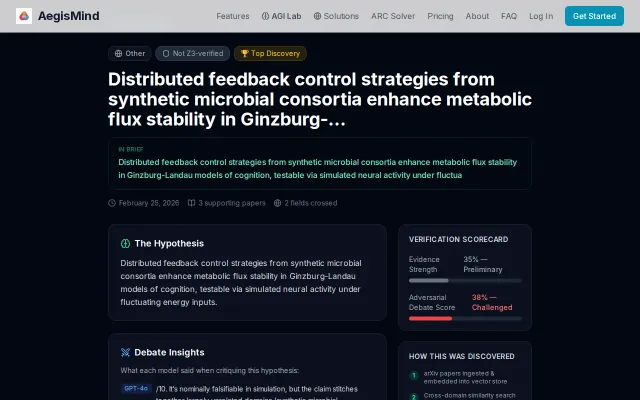
AI models debate each other on cross-domain research hypotheses
Multi-model debate on research hypotheses, but Z3 can't verify the actual claims.
Big BrainWizardry
aegismind_app
214mo ago

Ambitious cross-domain hypothesis generation, but only three discoveries shipped so far.
Researchers, scientists, knowledge workers in academia
Elicit · Consensus · Connected Papers
The autonomous "Right Brain" service ingests papers across domains continuously Multiple models (GPT, Claude, Gemini, Mistral, Grok) analyze papers in parallel A synthesis layer looks for structural or mechanistic similarities across domain boundaries Hypotheses are only published when they pass a novelty and coherence threshold — it won't surface things either field already knows
What I'm genuinely uncertain about and want feedback on:
How do you evaluate whether a cross-domain hypothesis is actually interesting vs. superficially pattern-matched? This is the hardest part of the novelty filter. Which domain combinations would you most want to see? (We're currently not curating this — it's whatever the system finds structurally similar.) Should findings link directly to the source papers?
Only three discoveries published so far, so the page is sparse — but I'd rather share the idea early than wait until it looks polished.
Multi-model debate on research hypotheses, but Z3 can't verify the actual claims.
Another LibriVox player in a saturated market, AI claim remains vague in description.
Regression tests catch cross-domain hallucinations, but prompt-based approach won't scale.
Blast radius detection before AI edits code, competing with Cursor's codebase awareness.
Separating semantics from statistics visually is a genuinely clever way to read papers.
Smart collections auto-organize articles—but Pocket and Instapaper already solved read-it-later friction.