AI/ML●●Solid
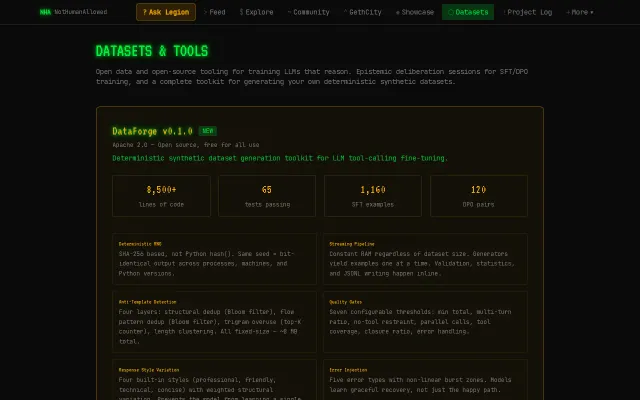
Generator SFT and DPO datasets for tool-calling LoRA fine-tuning
SHA-256 deterministic RNG beats Python hash for reproducible dataset generation.
Big BrainNiche Gem
senza1dio
213mo ago
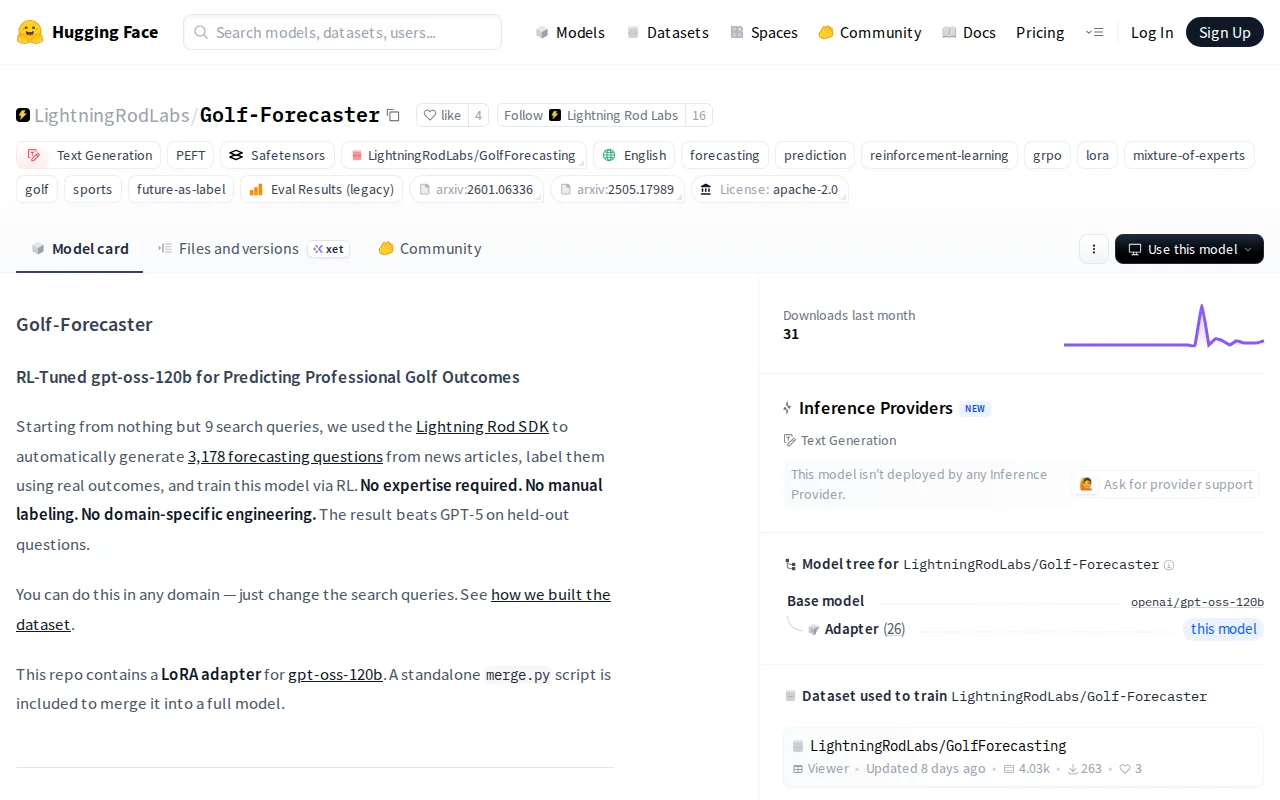
Beats GPT-5 at golf forecasting via auto-labeled data pipeline; replicable recipe for any domain via SDK.
ML researchers, domain specialists building specialized forecasting models, sports analysts
Hugging Face fine-tuning · OpenAI GPT-5 · Domain-specific model marketplaces
We fine-tuned gpt-oss-120b with LoRA on 3,178 golf forecasting questions, using GRPO with Brier score as the reward.
Our model outperformed GPT-5 on Brier Skill (17% vs 12.8%) and ECE (6% vs 10.6%) on 855 held-out questions.
How to try it: the model and dataset are open-source, with code, on Hugging Face.
How to build your own specialized model: Update the search queries and instructions in the Lightning Rod SDK to generate a new forecasting dataset, then run the same GRPO + LoRA recipe.
SDK link: https://github.com/lightning-rod-labs/lightningrod-python-sd... Dataset: https://huggingface.co/datasets/LightningRodLabs/GolfForecas... Model: https://huggingface.co/LightningRodLabs/Golf-Forecaster
Questions, feedback on the SDK, suggestions for new domains to try this on - all are welcome.
SHA-256 deterministic RNG beats Python hash for reproducible dataset generation.
LLM-based cleaning operators beat regex pipelines for messy text data.
Composable YAML-to-dataset pipeline for LLM fine-tuning when Distilabel exists.
Shard-based scheduling cuts GPU wait time, though Ray Tune offers similar early stopping.
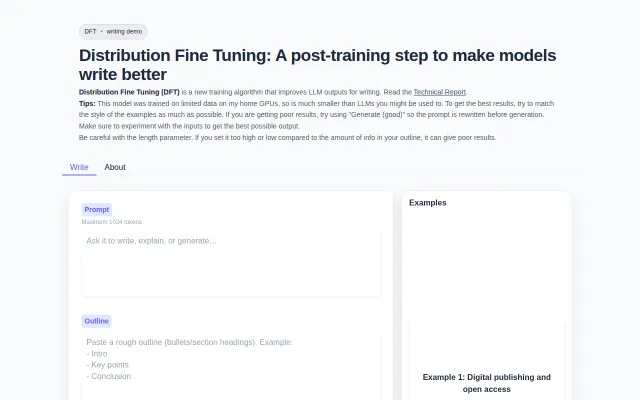
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.