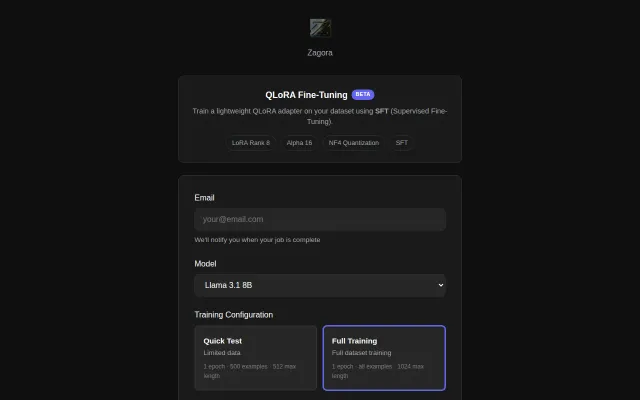
AI/ML●●Solid
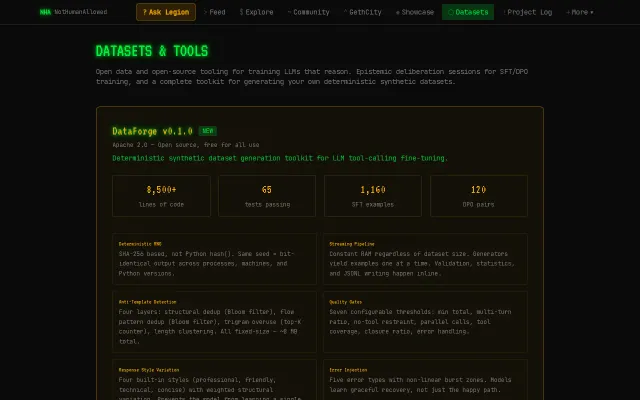
Generator SFT and DPO datasets for tool-calling LoRA fine-tuning
SHA-256 deterministic RNG beats Python hash for reproducible dataset generation.
Big BrainNiche Gem
senza1dio
213mo ago
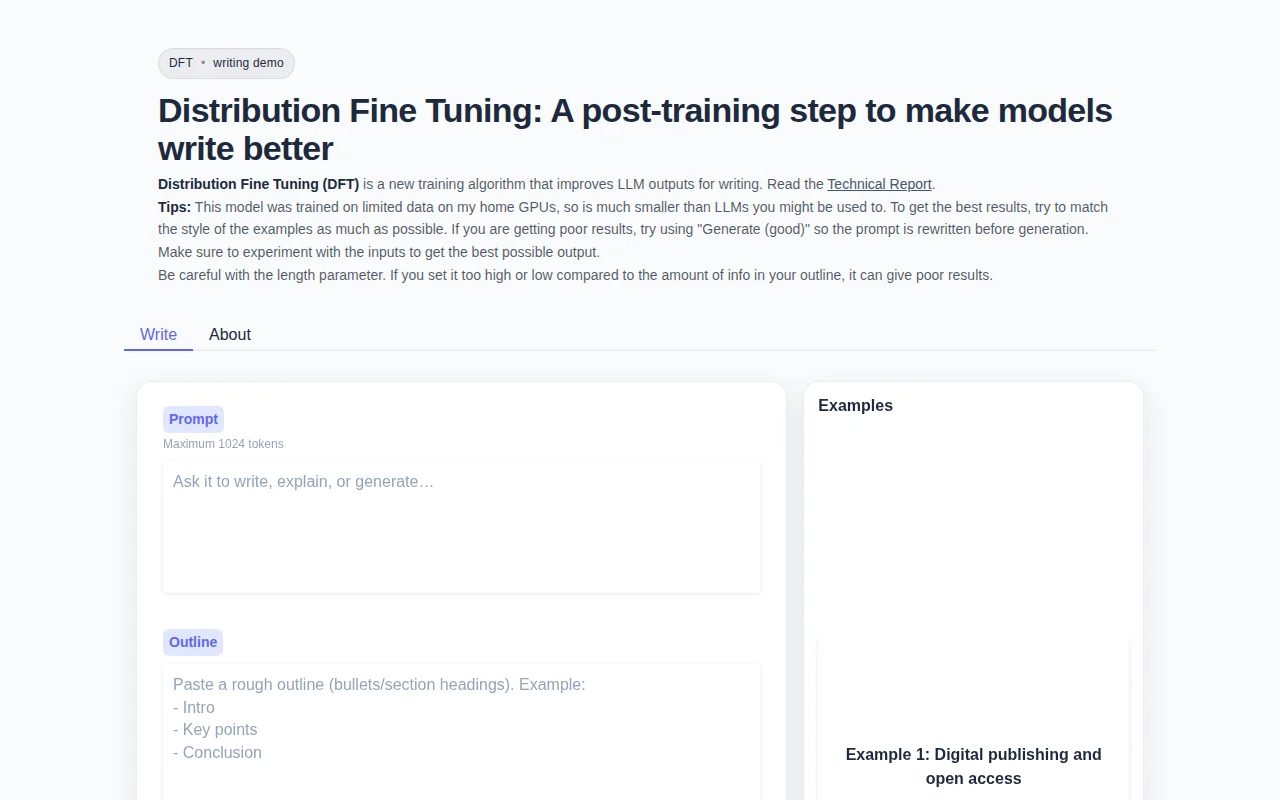
Novel fine-tuning algorithm for writing, but the demo model is too small to prove the concept.
LLM researchers and NLP engineers
DPO · ORPO · SimPO
I made a new training algorithm called Distribution Fine Tuning (DFT) to fix this.
The demo lets you try out a model trained with DFT.
More details in the technical report: https://rosmine.ai/2026/05/18/fixing-llm-writing-with-distri...
SHA-256 deterministic RNG beats Python hash for reproducible dataset generation.
BitTorrent-style distributed inference for biology LLMs across consumer GPUs.
Pipeline parallelism for mixed GPUs over internet, but unproven vs established frameworks.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.
Composable YAML-to-dataset pipeline for LLM fine-tuning when Distilabel exists.