Infrastructure●Mid
Trustmeplease.ai – trust, don't guess (a trust network for AI agents)
10-per-day trust scarcity is clever, but unclear if reputation actually guides agent selection vs. vanity metrics.
Bold BetShip It
kanelbullen
133mo ago
Bayesian autonomy for AI agents beats binary permission model with psychological insight.
AI agent developers, operational automation engineers, indie game studios
Anthropic Constitutional AI · Mechanistic interpretability research · Human-in-the-loop RL frameworks
To manage operations for my independent video game studio, I built a trust system that works more like onboarding a new hire. Agents start in draft mode (every action needs approval), and earn autonomy over time based on their track record in specific task categories.
The core idea: each agent maintains a separate Beta distribution per task category (support triage, expense reports, publisher emails, etc.). A Beta distribution is basically a track record parameterized by successes and failures. But raw E[p] = α/(α+β) can't tell the difference between "9 successes, 0 failures" and "90 successes, 10 failures" since both give E[p] = 0.90. So I use Jøsang's Subjective Logic to map these to opinion tuples that explicitly separate belief from uncertainty. High uncertainty means "not enough data yet," which is different from "we know this agent is bad."
Every action passes through a gate:
VoI = stakes × (1 - trust) × uncertainty
Low VoI = auto-execute. High VoI = draft for human review. Static trust thresholds set the maximum autonomy level an agent can reach (Auto-Execute, Soft-Execute, Draft, Restricted), and VoI acts as a secondary gate that can restrict it further based on context — an agent might qualify for auto-execute in general, but a high-stakes situation still gets flagged.Three things that made the biggest difference:
1. Edit distance feedback. If you rewrite half an email before hitting "approve," the system notices. A 0% edit = full trust credit. A 71%+ rewrite = penalty. This single change prevented agents from reaching auto-execute on work users were quietly fixing.
2. Time-based decay. Trust scores decay daily for inactive categories (λ = 0.95). If an agent hasn't done a task in two months, it gets supervised again. This also handles model upgrades, since the track record was earned on a different model.
3. Weakest-link chains. Multi-step workflows (send welcome email → create project → schedule meeting → notify team) use a weakest-link model. If any step needs approval, the whole chain surfaces as one inbox item. Nothing runs until you approve the full picture.
The core mapping from track record to opinion looks like this:
def beta_to_opinion(alpha, beta, base_rate=0.5): n = alpha + beta return Opinion( belief=(alpha - 1) / n, disbelief=(beta - 1) / n, uncertainty=2 / n, base_rate=base_rate, )
The math is all well-established (Beta distributions, Subjective Logic, Value of Information). The part that worked was combining them into something that mirrors how trust actually develops between people.Article with full implementation details, code examples, and diagrams: https://kenschachter.substack.com/p/earned-autonomy
10-per-day trust scarcity is clever, but unclear if reputation actually guides agent selection vs. vanity metrics.
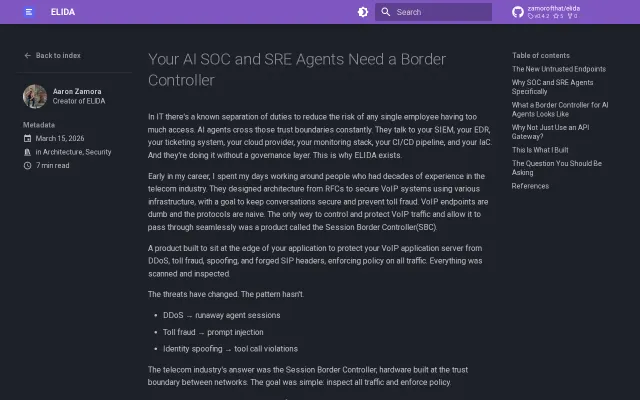
Telecom SBC patterns applied to AI agents, but no working implementation shown.
Agent Yellow Pages sounds cool but 100 users in a month proves demand is unclear.
Vouch decay prevents stale trust accumulation in a crowded agent reputation space.
Catches supply-chain attacks by verifying cryptographic attestations before pip install.
403 Forbidden error blocks access; can't evaluate a paper nobody can read.