Developer Tools●●Solid
Ext-Infer – Native LLM Inference and Embeddings for PHP
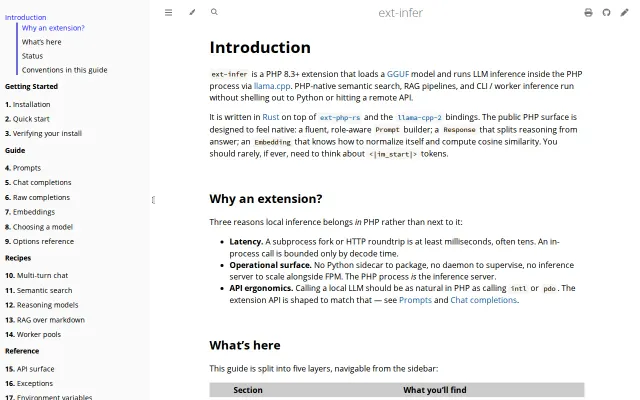
In-process LLM inference in PHP beats the usual Python sidecar pattern.
Big BrainNiche Gem
eamann
201mo ago
OmniDocs📄 - One stop visual document processing framework
Abstraction layer for document AI models, but orchestrating existing tools isn't novel.
ML engineers, AI pipeline builders working with document understanding and layout analysis tasks
LangChain · Unstructured.io · AWS Textract
I’m Adithya, a 22-year-old researcher from India. I work with a lot of document processing models while building AI pipelines, and one pain kept repeating: every model has its own inference code, preprocessing steps, and output format. Swapping models or testing new ones meant rewriting a lot of boilerplate each time.
So I built Omnidocs—an open source library to run document processing models through a simple, unified API, with a vision-first approach to understanding documents.
Key features:
> Pick a task and a model, run inference with one interface > Supports common document tasks: Text extraction, OCR, Table extraction, Layout analysis and Structured Extraction ... > 16+ models supported out of the box (many more integrations to come) > Runs locally on Mac or GPUs (MLX and vLLM backends supported) > Works with VLM APIs like GPT, Claude, Gemini and many more that support Open Responses API spec > Designed to quickly build and test document processing pipelines
This has helped me prototype document workflows much faster and compare models easily.
Would love feedback on the API design, developer experience, and what integrations would make this more useful.
In-process LLM inference in PHP beats the usual Python sidecar pattern.
Resumable stages prevent multi-hour extraction losses when APIs fail.
LLM-as-judge metrics beat guessing chunk sizes, but Ragas and LangSmith already exist.
AI wrapper for KYC when Onfido, Jumio, and Veriff already dominate this space.
Uncensored briefs on sensitive docs without account/storage; Venice zero-retention solves real hallucination risk.
Civ-style tech tree for AI agent standards—good explainer, but presentation over substance.