Infrastructure●●Solid
ZSE – Single-file LLM engine with dual INT4 kernels
INT4 inference engine beats llama.cpp on VRAM, but competing against established tools.
WizardryShip It
zyoralabs
104mo ago
The inference engine the open-source world built for itself.
3.9s cold starts vs 45s+ for quantized models—real infra pain solved tangibly.
ML engineers deploying LLMs on limited VRAM or serverless platforms; cost-conscious inference teams
vLLM · bitsandbytes · llama.cpp
The problem I was trying to solve: Running a 32B model normally requires ~64 GB VRAM. Most developers don't have that. And even when quantization helps with memory, cold starts with bitsandbytes NF4 take 2+ minutes on first load and 45–120 seconds on warm restarts — which kills serverless and autoscaling use cases.
What ZSE does differently:
Fits 32B in 19.3 GB VRAM (70% reduction vs FP16) — runs on a single A100-40GB
Fits 7B in 5.2 GB VRAM (63% reduction) — runs on consumer GPUs
Native .zse pre-quantized format with memory-mapped weights: 3.9s cold start for 7B, 21.4s for 32B — vs 45s and 120s with bitsandbytes, ~30s for vLLM
All benchmarks verified on Modal A100-80GB (Feb 2026)
It ships with:
OpenAI-compatible API server (drop-in replacement)
Interactive CLI (zse serve, zse chat, zse convert, zse hardware)
Web dashboard with real-time GPU monitoring
Continuous batching (3.45× throughput)
GGUF support via llama.cpp
CPU fallback — works without a GPU
Rate limiting, audit logging, API key auth
Install:
----- pip install zllm-zse zse serve Qwen/Qwen2.5-7B-Instruct For fast cold starts (one-time conversion):
----- zse convert Qwen/Qwen2.5-Coder-7B-Instruct -o qwen-7b.zse zse serve qwen-7b.zse # 3.9s every time
The cold start improvement comes from the .zse format storing pre-quantized weights as memory-mapped safetensors — no quantization step at load time, no weight conversion, just mmap + GPU transfer. On NVMe SSDs this gets under 4 seconds for 7B. On spinning HDDs it'll be slower.
All code is real — no mock implementations. Built at Zyora Labs. Apache 2.0.
Happy to answer questions about the quantization approach, the .zse format design, or the memory efficiency techniques.
INT4 inference engine beats llama.cpp on VRAM, but competing against established tools.
Local indexer with AST + impact graph replaces grepping and cloud RAG for code context.
94% GPU reduction claim needs verifiable benchmarks to stand out.
Entity-centric memory cuts context 90% while matching full-text performance on NovelQA.
Academic paper on TTFT optimization with no implementation to evaluate.
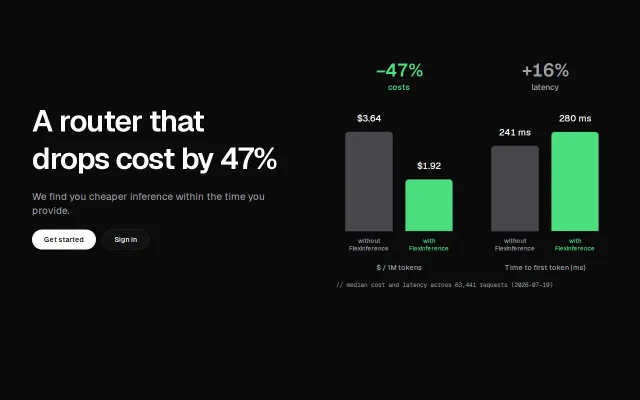
Races cheap flex tiers against your latency budget to slash inference bills automatically.