Developer Tools●●●Banger
Docdex – A local tool to reduce LLM tokens and make agents smarter
Local indexer with AST + impact graph replaces grepping and cloud RAG for code context.
WizardrySolve My ProblemZero to One
bekirdag
103mo ago
Academic paper on TTFT optimization with no implementation to evaluate.
ML engineers and researchers working on LLM inference optimization
vLLM · TGI (Text Generation Inference) · SGLang
Local indexer with AST + impact graph replaces grepping and cloud RAG for code context.
Token-efficient code indexing with adaptive callers tracing cuts Claude costs by 34%.
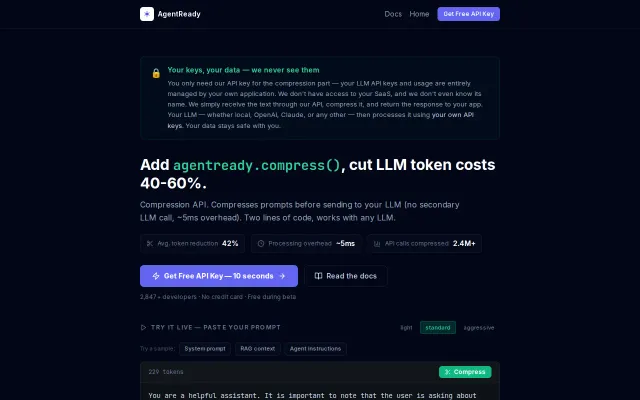
Prompt compression cuts token costs 40-60%, but prompt optimization isn't new.
Applies CPU cache coherence protocols to multi-agent LLM synchronization—clever analogy.
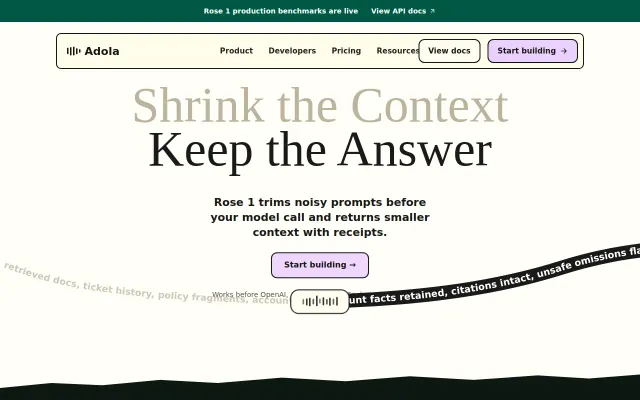
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
Replaces O(n²) token re-parsing with true O(n) streaming; Vercel SDK does 4K re-parses on 50KB payloads.