AI/ML●●Solid
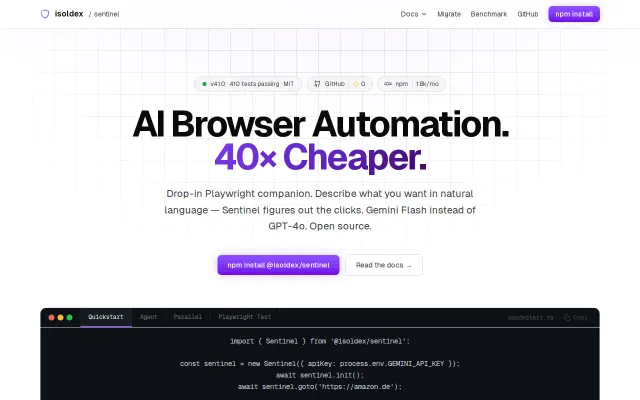
Sentinel – LLM browser automation using 10x fewer tokens
Token efficiency beats Stagehand — 2-5k vs 29-51k per action with cached selectors.
Solve My ProblemSlick
isoldex
101mo ago
The fastest AI browser. Zero telemetry. Open source. 3-10x fewer tokens.
Referenced element indexing cuts token spend 3-10x versus DOM-dumping AI browsers.
AI automation engineers, web scraping developers, cost-conscious LLM users
Perplexity Comet · ChatGPT Atlas · Cursor Browser
Token efficiency beats Stagehand — 2-5k vs 29-51k per action with cached selectors.
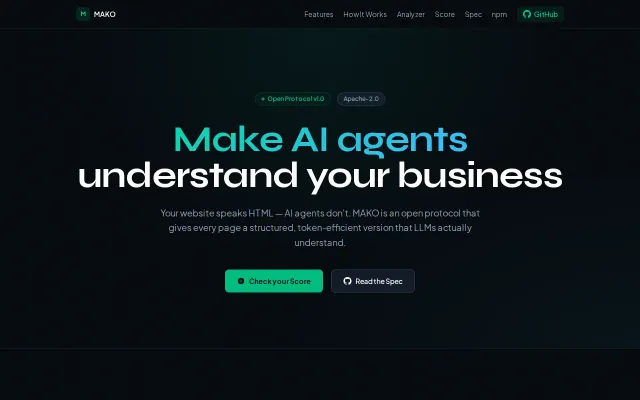
MAKO compresses what matters into a HEAD-friendly payload — frontmatter, declared actions and semantic links — so agents can find relevance without downloading 181KB of navigation, ads and scripts. The project ships a spec plus real tooling (typed SDK, Express middleware, an analyzer/score and edge-friendly /md conversion), which is a rare combo of protocol thinking and usable developer ergonomics. Whether it becomes a standard depends on buy-in from CMS/plugin authors and agent platforms, but technically it's a smart, practical swing at an obvious pain point.
Cuts agent token costs by 98% compared to grep without needing GPU inference.
Static Model2Vec embeddings beat transformer retrieval quality while running entirely on CPU.
Independent search index in Rust when Tavily and Serper wrap Google.
Self-benchmark shows Sentinel uses 57x fewer tokens than browser-use on hard tasks.