Developer Tools●●Solid
Token-saviour – agent skill from benchmarking 9 token-saving tools
Benchmark-backed router cuts agent token costs by 70% across four task layers.
Big BrainSolve My Problem
vagkaratzas
2410d ago
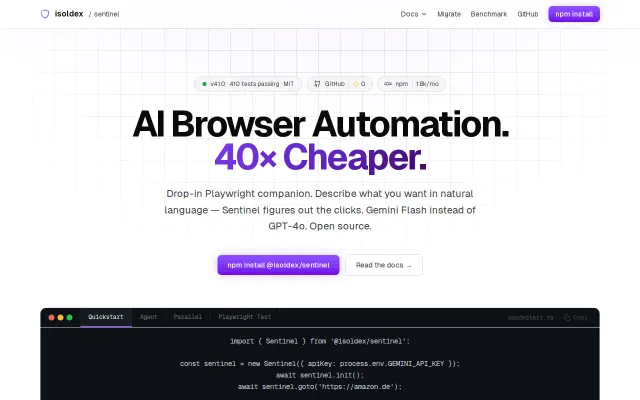
Self-benchmark shows Sentinel uses 57x fewer tokens than browser-use on hard tasks.
Developers building AI browser automation agents
BrowserUse · Stagehand · LangChain
Benchmark-backed router cuts agent token costs by 70% across four task layers.
Token efficiency beats Stagehand — 2-5k vs 29-51k per action with cached selectors.
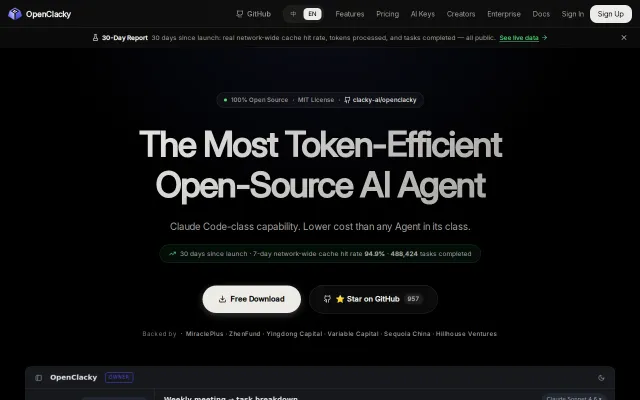
94.9% cache hit rate cuts token costs, but AI agent wrappers are crowded.
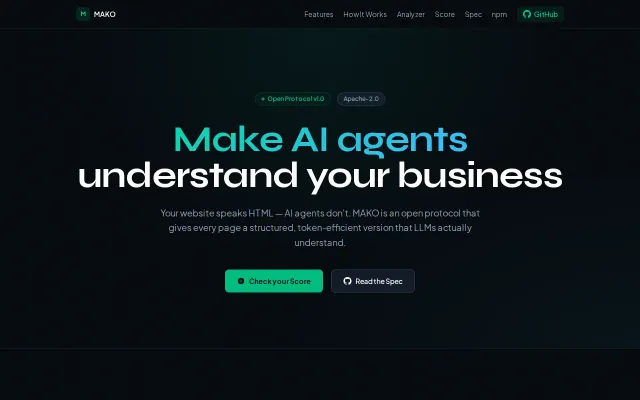
MAKO compresses what matters into a HEAD-friendly payload — frontmatter, declared actions and semantic links — so agents can find relevance without downloading 181KB of navigation, ads and scripts. The project ships a spec plus real tooling (typed SDK, Express middleware, an analyzer/score and edge-friendly /md conversion), which is a rare combo of protocol thinking and usable developer ergonomics. Whether it becomes a standard depends on buy-in from CMS/plugin authors and agent platforms, but technically it's a smart, practical swing at an obvious pain point.
Token-efficient word IDs for LLMs, but it's a narrow utility library.
Entity-mapped web search API cuts agent token waste; targets real Perplexity/Anthropic use case.