AI/ML●●Solid
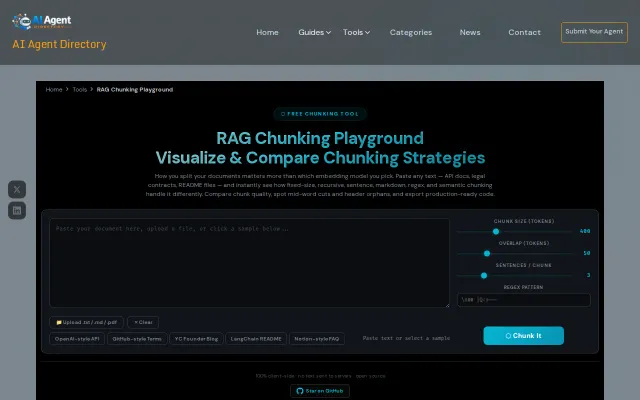
RAG chunking playground: visualize how your docs get split
Visual chunking comparison beats guessing — export production-ready code.
Solve My ProblemNiche Gem
Horatius77
101mo ago
⚡ Production-grade RAG chunking engine powered by Rust. Process GBs of CSV, PDF, JSON, JSONL, DOCX, XLSX, URLs, ETC., in seconds with O(1) memory. 40x faster than LangChain.
Rust core beats LangChain's Python bottleneck, but chunking alone won't move the needle.
RAG/LLM engineers, ML ops teams, vector database users
LangChain RecursiveCharacterTextSplitter · Llamaindex SimpleNodeParser · Unstructured.io
The problem: LangChain's chunker is pure Python and becomes a bottleneck at scale — slow and memory-hungry on large document sets.
What Krira Chunker does differently: - Rust-native processing — 40x faster than LangChain's implementation - O(1) space complexity — memory stays flat regardless of document size - Drop-in Python API — works with any existing RAG pipeline - Production-ready — 17 versions shipped, 315+ installs
pip install krira-augment
Would love brutal feedback from anyone building RAG systems — what chunking problems are you running into that this doesn't solve yet?
Visual chunking comparison beats guessing — export production-ready code.
LLM-as-judge metrics beat guessing chunk sizes, but Ragas and LangSmith already exist.
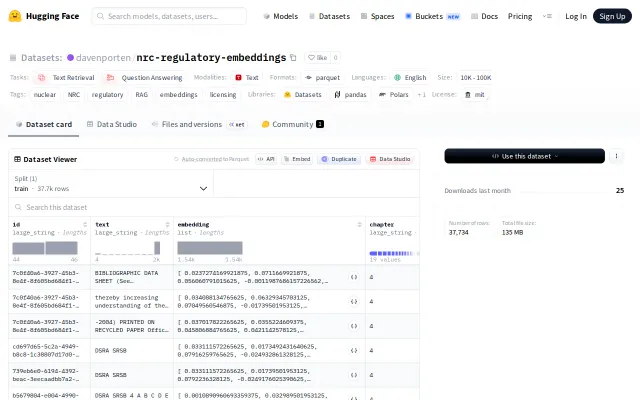
First public NRC regulatory embeddings dataset—37K chunks ready for ChromaDB and Pinecone.
Exports a one-file 'brain' and a tiny MemoryOrchestrator API (remember/recall) so you can ditch Docker and hosted vector DBs — token-budgeted, deterministic recall and kill-9-safe durability are concrete wins. The Metal-accelerated vector search plus SQLite FTS5 fallback shows real engineering heft, but it's clearly tuned for the Apple ecosystem and the author is still asking for retrieval/eval feedback.
Rust rewrite with PDFium delivers 100x speedup over the Python v1.
SIEVE cache beats LRU with one-line swap, but only matters if you're bottlenecked on cache.