AI/ML●●Solid
Autoretrieval – Autoresearch for RAG Pipelines
Auto-edits retrieval code to boost F-beta scores when standard eval frameworks stay static.
Big BrainShip It
Daly_chebbi
328d ago
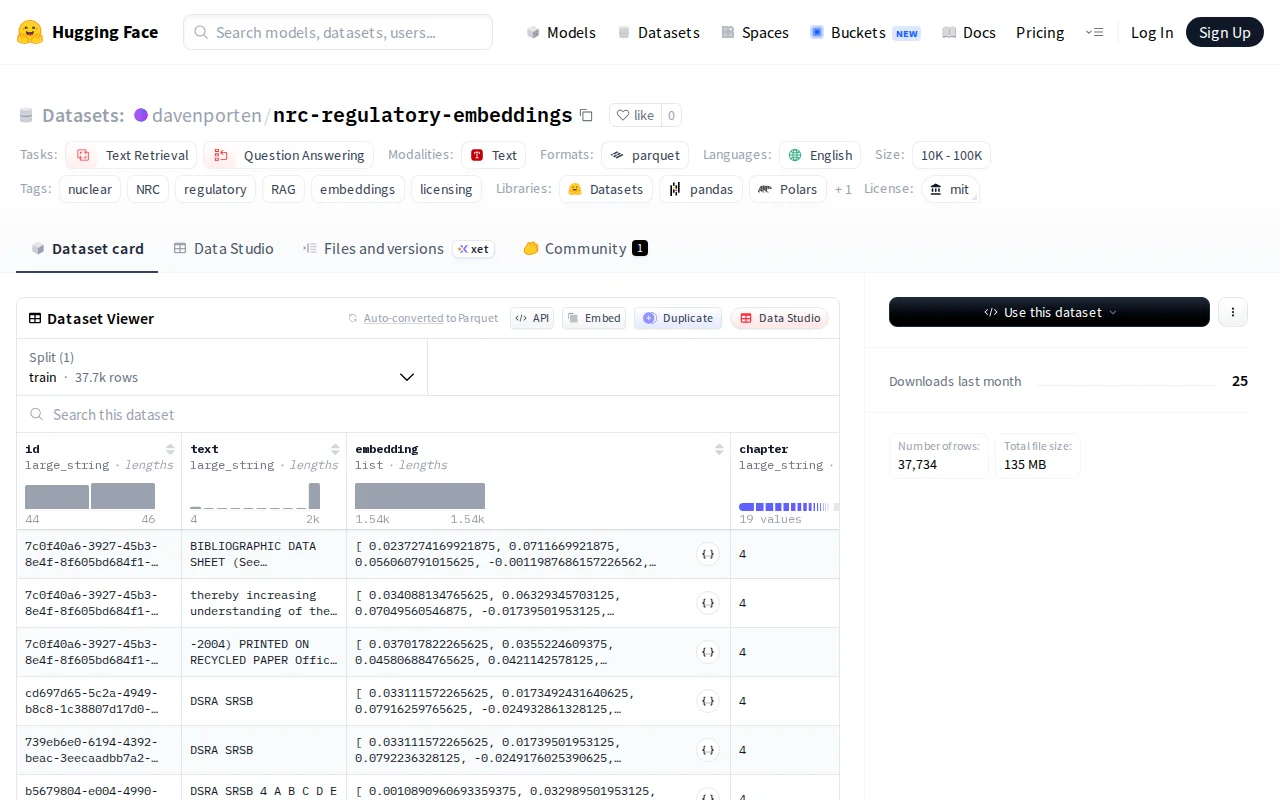
First public NRC regulatory embeddings dataset—37K chunks ready for ChromaDB and Pinecone.
AI engineers building regulatory compliance systems, nuclear industry developers
What I think is the most interesting artifact is the dataset: 37,734 chunks of NRC regulatory documents (NUREG-0800, 10 CFR Parts 20/50/51/52/72/73/100, and Regulatory Guides) embedded with OpenAI text-embedding-3-small. It covers the full regulatory corpus an applicant would need for a COL submission. I'm not aware of anything like this being publicly available before.
The embeddings are ready to load directly into ChromaDB, Pinecone, or any other vector store. If you're doing nuclear AI, regulatory NLP, or just want a large real-world RAG dataset to experiment with, it should be useful.
Here's the full codebase if you're interested: https://github.com/Davenporten/nrc-licensing-rag
Auto-edits retrieval code to boost F-beta scores when standard eval frameworks stay static.
LLM-as-judge metrics beat guessing chunk sizes, but Ragas and LangSmith already exist.
Modular RAG with MCP integration, but Langchain and LlamaIndex already dominate.
Chunk-level incremental sync saves 67% embedding calls on partial document edits.
RAG library with serve command, but Langchain, LlamaIndex, and Verba already dominate.
ESLint for RAG pipelines that avoids using AI to debug AI hallucinations.