AI/ML●●Solid
Palinode – Git-versioned Markdown memory for AI agents
Markdown files as source of truth means you can always grep your agent's memory.
Big BrainNiche Gem
paulkyle
202mo ago
🫛👣 FAVA Trails — Git-native, curated memory for AI agents via MCP. Draft isolation, promotion gate, thought lifecycle hooks, memory curation protocols, supersession chains.
Fixes agent memory poisoning using Jujutsu VCS—solves contradictory beliefs problem elegantly.
AI agent developers and autonomous system builders concerned with memory reliability.
LangChain memory modules · Chroma vector memory
I've been building and running autonomous AI agents (recently consulting on systems testing high on MLE-Bench), and I kept hitting the exact same architectural wall: memory poisoning.
Right now, the industry standard for agent memory is to dump text into storage with very little thought about correctness. If an agent hits a transient network error and writes "this environment has no GPU" to its memory, and later realizes it actually does have a GPU and writes a correction... a standard vector search returns both. Your agent is now schizophrenic, holding contradictory beliefs because they are semantically similar.
Furthermore, memory systems are mostly "write-through." If a user jailbreaks your bot into an offensive persona, the bot saves that as a "user preference" and it persists across sessions forever. We don't let untested code reach main, so why do we let unvalidated agent thoughts reach shared memory?
I built FAVA Trails to fix this. It's an agentic memory layer that uses Jujutsu (JJ) version control under the hood.
For the version control nerds: why Jujutsu? I originally looked at standard Git and SQL-based VCS like Dolt. But JJ is the perfect substrate for autonomous agents. Its conflict resolution, first-class operation log, and the fact that the working copy is a commit makes it inherently crash-proof for long-running agent scripts. If an agent session crashes mid-thought, the JJ commit is already there. No detached HEAD nightmares, no staging area rituals for the agent to mess up. Just atomic state snapshots. (It's colocated with Git, so you can still push the data to a standard remote).
How it works:
- Draft Isolation: Agents write to a local draft namespace first. It doesn't pollute shared memory.
- Trust Gate: A mandatory promotion workflow. An independent LLM (or explicit human approval) reviews the draft before it merges into canonical truth.
- Supersession Chains: Corrections don't silently overwrite history. They link back to it, so you get a full causal graph of why the agent changed its mind.
- MCP Native: It runs as a Model Context Protocol (MCP) server, so agents interact with it via semantic tools (recall, save_thought, propose_truth) and never run VCS commands directly.
It's Apache 2.0 and strictly a pip-installable tool (no cloud lock-in, the data is just Markdown files with YAML frontmatter in your own repo).
Repo: https://github.com/MachineWisdomAI/fava-trails Case Study/Docs: https://fava-trails.org
I'd love to hear your thoughts on using JJ as a backend for state, or how you're handling the "gaslighting agent" problem in your own multi-agent stacks.
Markdown files as source of truth means you can always grep your agent's memory.
Git branches for agent memory with time-travel rollback via MatrixOne CoW engine.
Jujutsu UI with agent-aware diff re-anchoring; keyboard-first, instant revision history replay.
Git for agent memory beats Letta's file-level versioning with zero-copy branching.
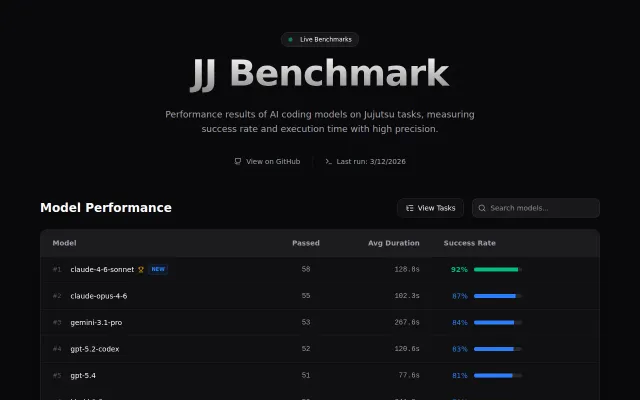
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.
First VCS with patch-based merging that's actually git-compatible.