Infrastructure●●Solid
AI Cost Firewall – OpenAI-compatible gateway with semantic caching
LLM gateway with Redis + Qdrant caching, but LiteLLM does this.
SlickShip It
vcaluser
113mo ago
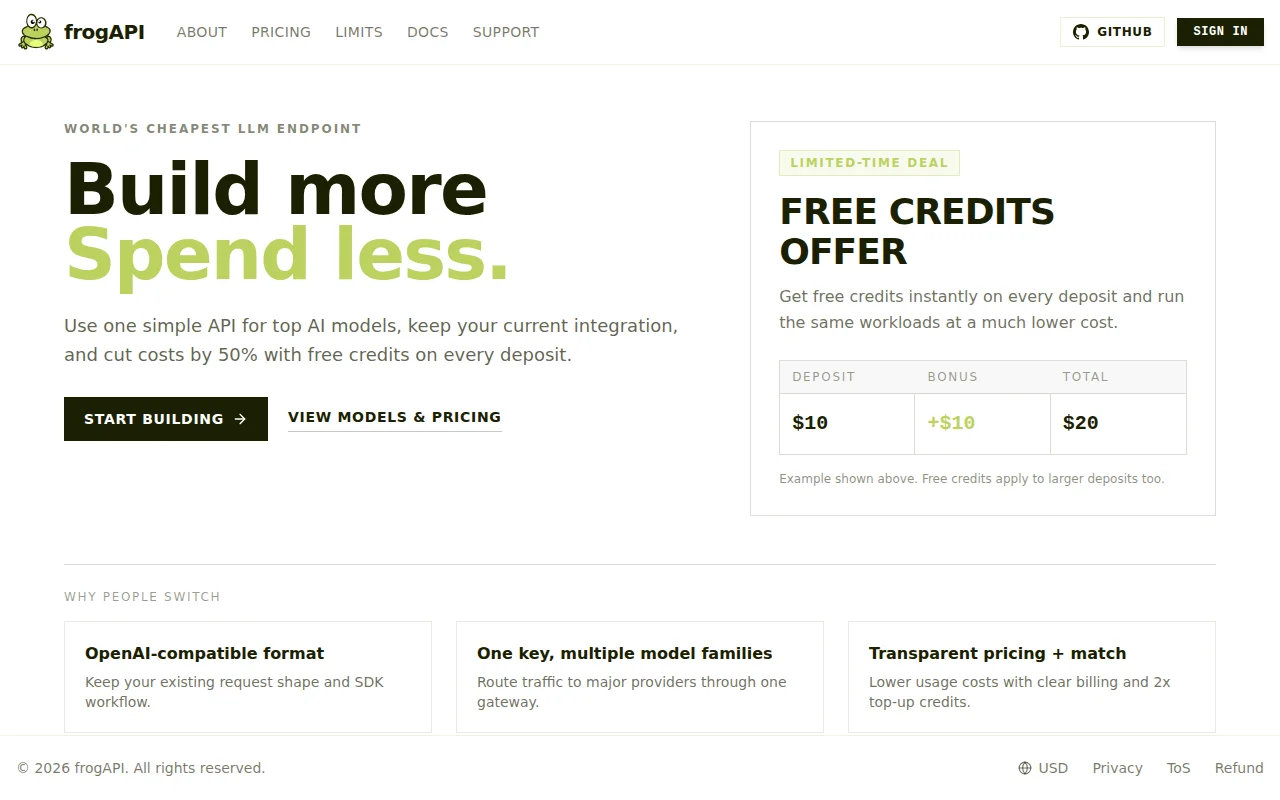
LLM API gateway with 2x credit matching, but model names appear fabricated.
AI application developers managing multi-model inference and cost optimization
Lambda Labs · Together AI · Anthropic API
It's an OpenAI-compatible API gateway. Swap your base URL to frogapi.app/v1, keep your SDK code, and pick from 9 models: GPT-5.2, GPT-5-Mini, GPT-5-Nano, DeepSeek-V3.2, Mistral-Large-3, Llama-4-Maverick, Kimi-K2.5, Grok-4.1-Fast, GPT-OSS-120B.
Per-token pricing matches the source models exactly. The way it works out cheaper: every deposit is matched with free credits. Put in $10, get $20 in credits. So your effective cost per token is half.
No subscriptions, no tiers. Pay per token.
Would love feedback.
LLM gateway with Redis + Qdrant caching, but LiteLLM does this.
Lets you keep the Claude Code UI while burning your ChatGPT Plus credits instead.
Yet another OpenAI API reseller with manual key delivery and no technical innovation.
Runs as a single binary with embedded SQLite and zero-config start, acting as a transparent, provider-agnostic proxy that logs model, tokens, latency, cost and API key hashes while leaving full body capture opt-in. It also proxies streaming responses in real time and exposes stable JSON analytics endpoints — a practical, instrumentable way to get reproducible, audit-ready traces for real LLM traffic, though long-term value depends on how it handles provider edge-cases and SDK compatibility.
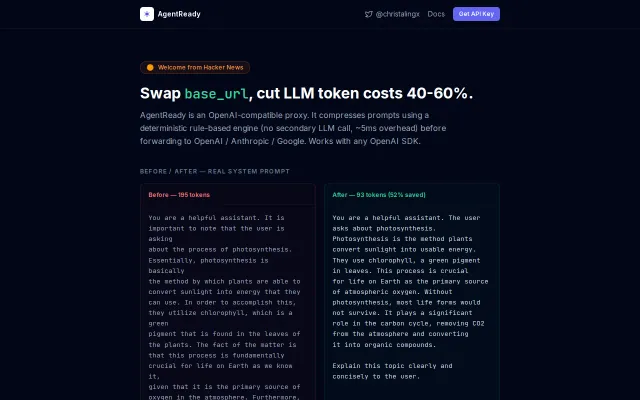
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.
AI tools scored by AI agents, but the methodology isn't transparent.