AI/ML●●●Banger
OpenJet – An offline agent harness for memory-constrained edge hardware
Context condensing under memory pressure solves the actual pain of edge AI agents.
Niche GemSolve My ProblemShip It
lforster
103mo ago
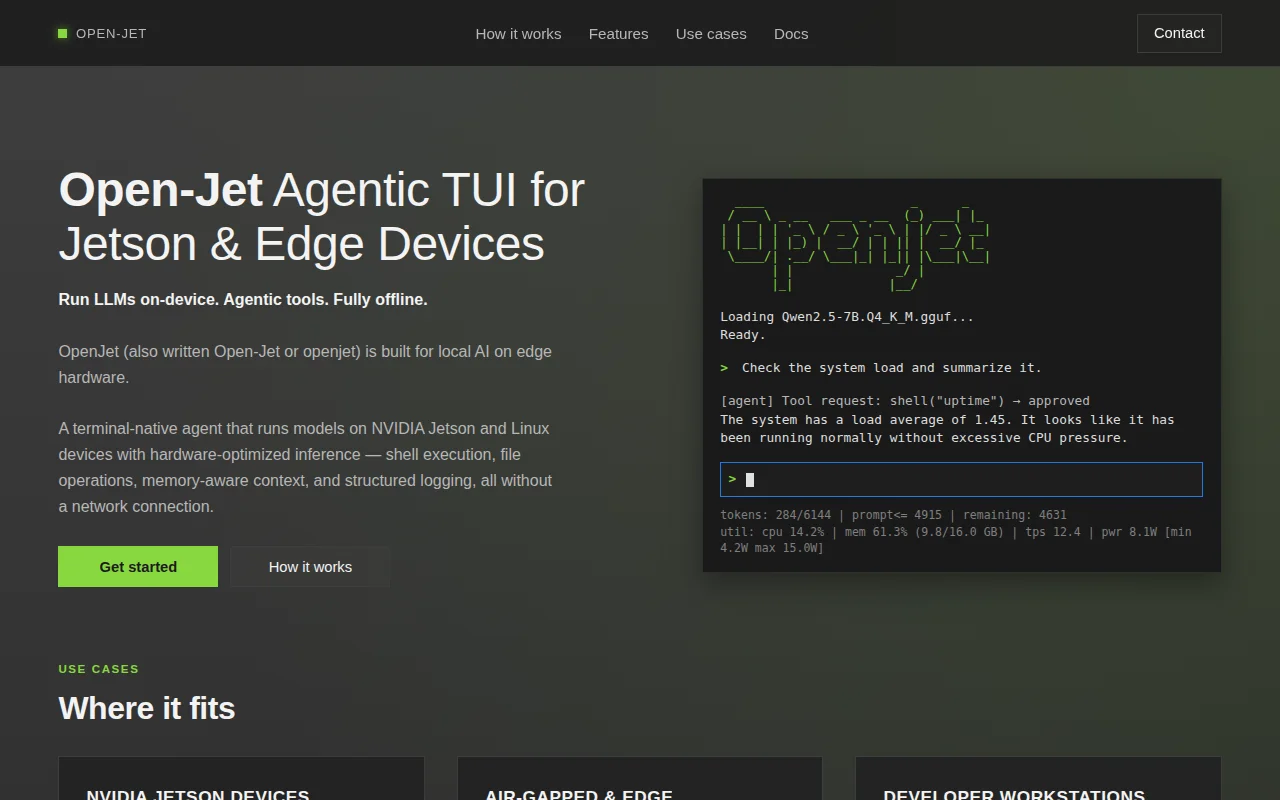
Terminal agent for Jetson with memory-aware context windowing and TensorRT optimization.
ML engineers, edge device developers, air-gapped deployment teams
I am building a Terminal User Interface (like Claude Code) for self-hosted AI agents on Jetsons. Works in air-gapped environments. Unlike other solutions, this is optimised for unified memory machines, as to avoid OOM errors.
The agent can do stuff like edit, read, create files - manage and interpret data locally.
Currently, it gets ~17 tok/s on Jetson Orin Nano 8GB using Qwen3-4B-Instruct-4bit In the future, adding TensorRT .engine support which will boost inference further. I am trying to get the memory footprint down, so if anyone has knowledge on kv cache optimisation, that would be great.
I would love to get your feedback and people try running it on more capable devices and models - post your results here.
Run ``` pip install open-jet open-jet --setup ```
Webiste: https://www.openjet.dev/ Directly on Pypi: https://pypi.org/project/open-jet/ Repo: https://github.com/L-Forster/open-jet/
Context condensing under memory pressure solves the actual pain of edge AI agents.
Quoracle actually does something interesting: it queries a pool of models and only executes actions they agree on, while letting agents spawn children and persist full state to Postgres — all visible in a LiveView dashboard. The per-model conversation history, recursive hierarchy, and explicit consensus pipeline are clever touches; it’s clearly aimed at experimentation rather than drop-in production use (the README even flags security and deployment caveats).
No LLM in the critical path — deterministic retrieval beats vector search latency.
Agents onboard themselves via llm.txt and pay crypto — genuinely novel email infrastructure.
Prompt library for the new Vercel Skills CLI, but mostly just text macros.
Guards tool outputs against injection attacks, unlike LiteLLM or Helicone.