Productivity●●Solid
I treated my CV like a data product-evidence.json,MCP endpoint,llms.txt
Evidence-mapped CV beats PDF for AI recruiter parsing, but applies only to ATS that read these formats.
Big BrainShip It
vassilbek
104mo ago
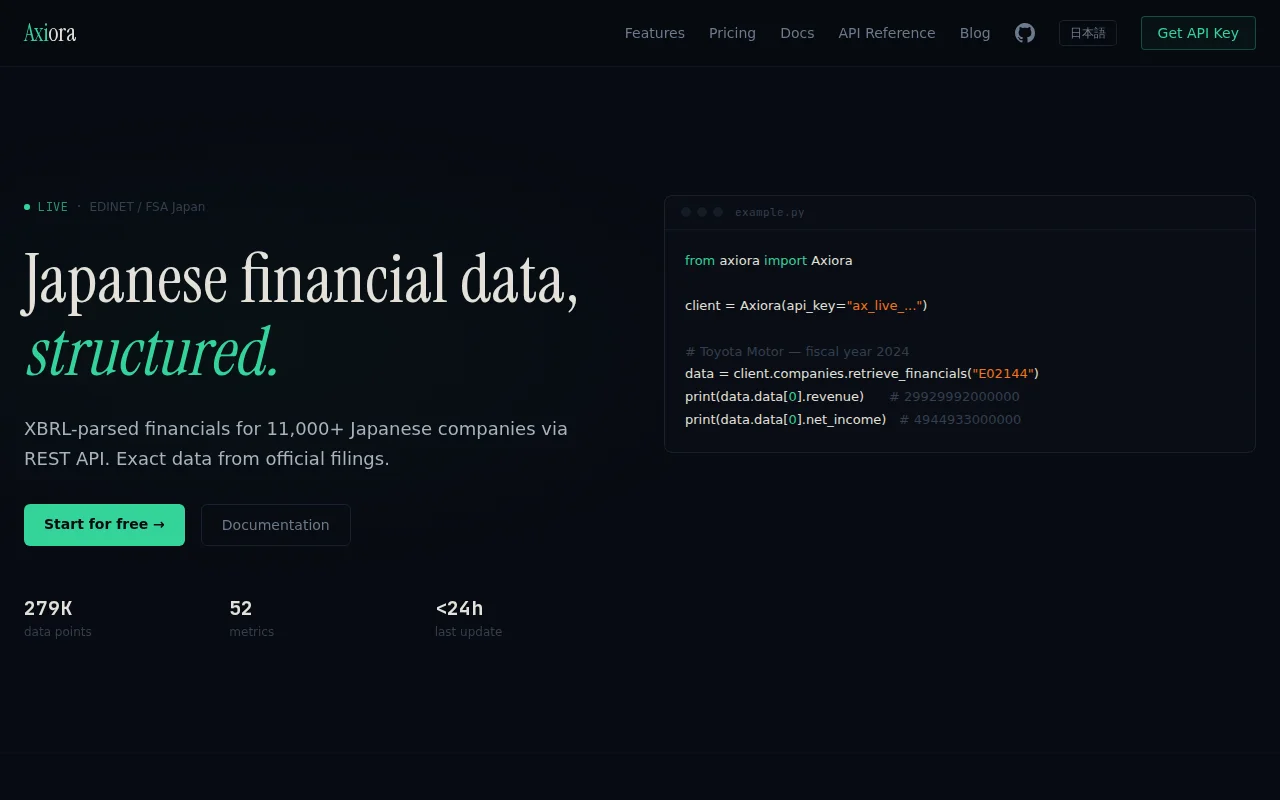
Unlocked Japanese financial data—XBRL parsed to JSON for 11k companies, no signup.
Quants, fintech engineers, researchers analyzing Japanese equities; no signup required to start.
Alpha Vantage · Finnhub · SEC Edgar API
Japan is the world's 4th largest stock market, but its financial data is stuck in the 90s. Corporate filings go through EDINET — a government system that stores everything as XBRL in Japanese, with 3 different accounting standards (JP-GAAP,IFRS, US-GAAP), company-specific taxonomies, and no usable API.
I've been working with Japanese XBRL filings for 2 years. I built a parser that normalizes all of it into structured JSON. Axiora now covers 4,125 listed companies with ~10 years of history and 52 financial fields per company-year.
Built for developers:
· REST API with full OpenAPI spec — https://axiora.dev/docs · Python SDK: pip install axiora · LangChain integration: pip install langchain-axiora (20 tools) · MCP server for Claude, ChatGPT, Cursor, etc. · llms.txt at axiora.dev/llms.txt
Try it now, no signup: https://axiora.dev/terminalRoadmap: TDNet integration (real-time timely disclosures from JPX) and stock prices are next. Data licenses are expensive and I'm bootstrapping this solo, so those will come as paid tiers.
Tech: Python/FastAPI on Cloud Run, Supabase (Postgres), lxml for XBRL parsing.
Free tier: 10,000 req/day. I'd love feedback on the API design or what data would be most useful.
Evidence-mapped CV beats PDF for AI recruiter parsing, but applies only to ATS that read these formats.
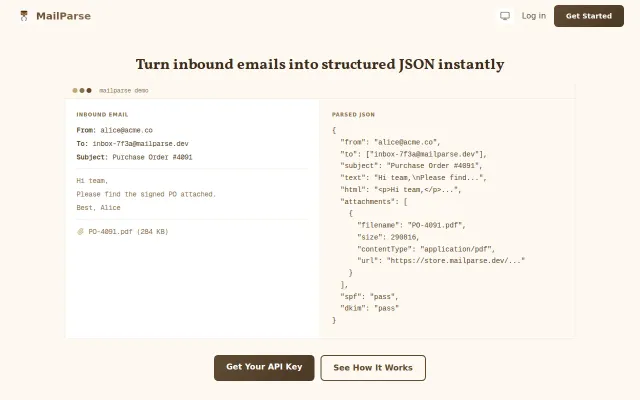
Clean inbound email parsing when Mailgun and SendGrid already do this.
x402 micropayments kill API keys entirely, letting agents pay per parse with zero auth overhead.
Compressed JSON bundles fit tight context windows better than pasting files.
473x faster YAML parsing via mmap cache with near-zero memory on hot reload.
First MCP server bringing real game save data into Claude and ChatGPT conversations.