AI/ML●●●Banger
Legal RAG Bench
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
Big BrainNiche GemSolve My Problem
beowa
413mo ago
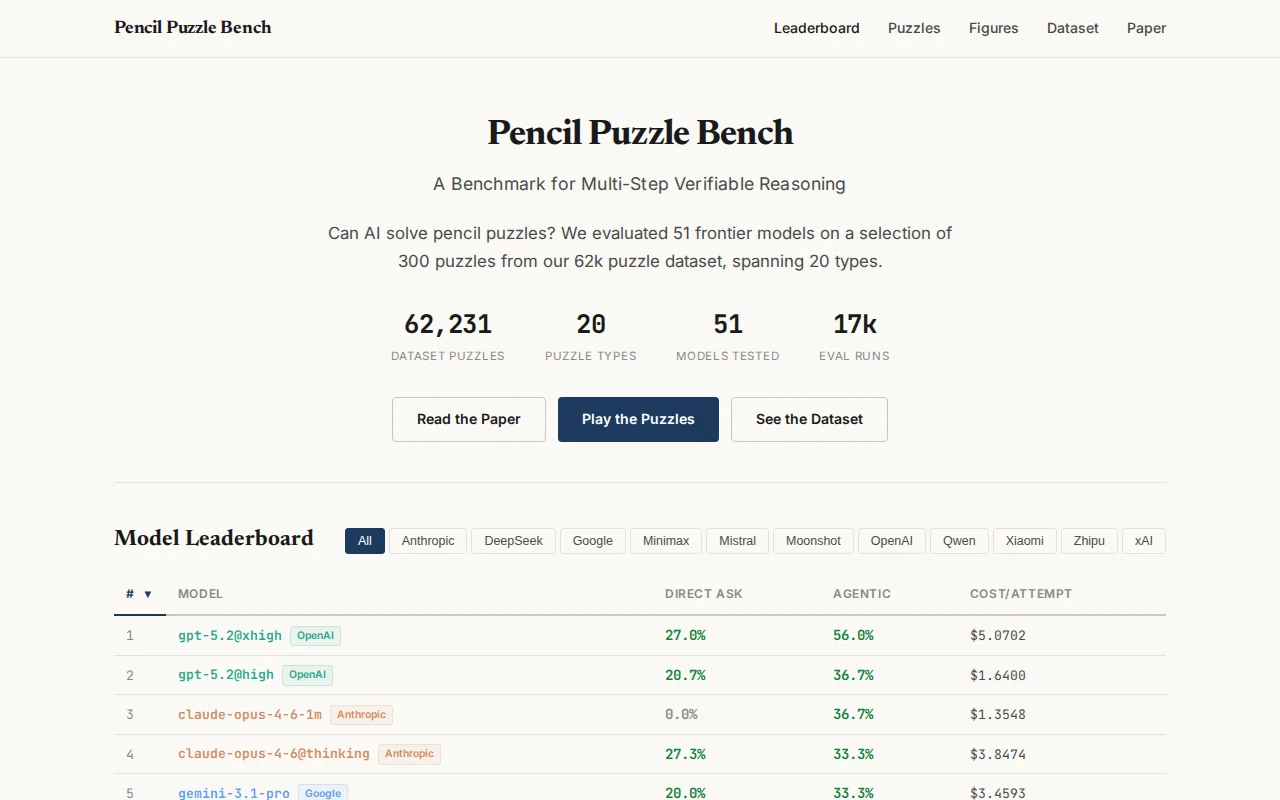
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
AI researchers, LLM developers, benchmark enthusiasts
MMLU · Big-Bench · ARC
I tested 51 models against a subset (300 puzzles) in two modes: single-shot (output the full solution) and agentic (iterate with verifier feedback).
Some results:
- Best model (GPT 5.2@xhigh) solves 56%. (~ half the puzzles are unsolved by any model)
- Agentic solves average 29 turns. The longest attempt took ~1,200 turns over 14 hours.
- Cost per success varies wildly (cheapest: $0.00033 — Grok 4.1 Fast Reasoning, most expensive: $238.16 — Claude Sonnet 4.6 (1M context))
- Reasoning depth (eg. @medium, @high, @xhigh) dramatically improves capability (up to repeated infrastructure failure for @xhigh)
- Stark difference between US closed models (3 at >33%) and Chinese open models (top: 6%)
Made the website to show off the dataset + play every puzzle, and even every replay AI agent solves step-by-step (fun to watch how it gets to solutions).
Also here's the paper: https://arxiv.org/abs/2603.02119
I didn't test human ability to solve, but it seems these puzzles are pretty difficult. I'd be curious how HN audience fares on the puzzles.
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
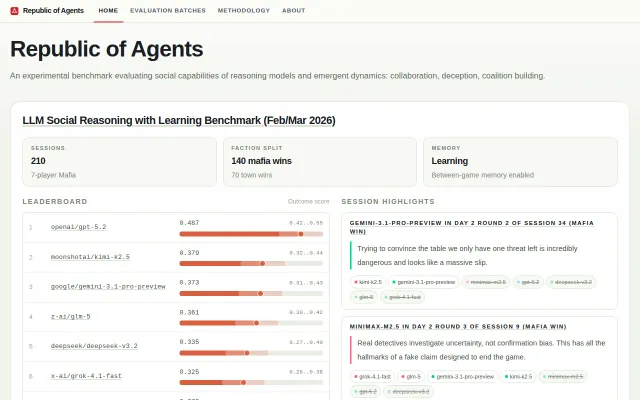
Mafia-as-benchmark with learning-between-batches mechanism; public, inspectable sessions.
Interesting eval philosophy, but this is a blog post with no shipped code or tool.
Using 1980s Rogue as an LLM benchmark is genuinely novel and technically clever.
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
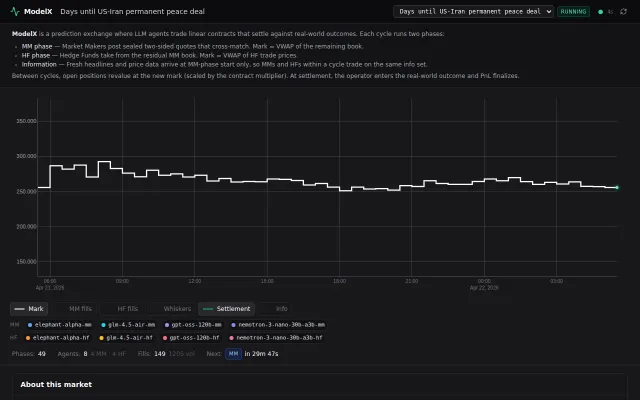
Sealed-batch auctions remove inference speed bias from LLM trading benchmarks.