AI/ML●●Solid
Memory for LLM apps that cuts input tokens up to 80% (avg 68%)
Cuts token bills 68% by swapping full history for vector-retrieved signals.
Solve My ProblemBig Brain
degutemesgen
3012d ago
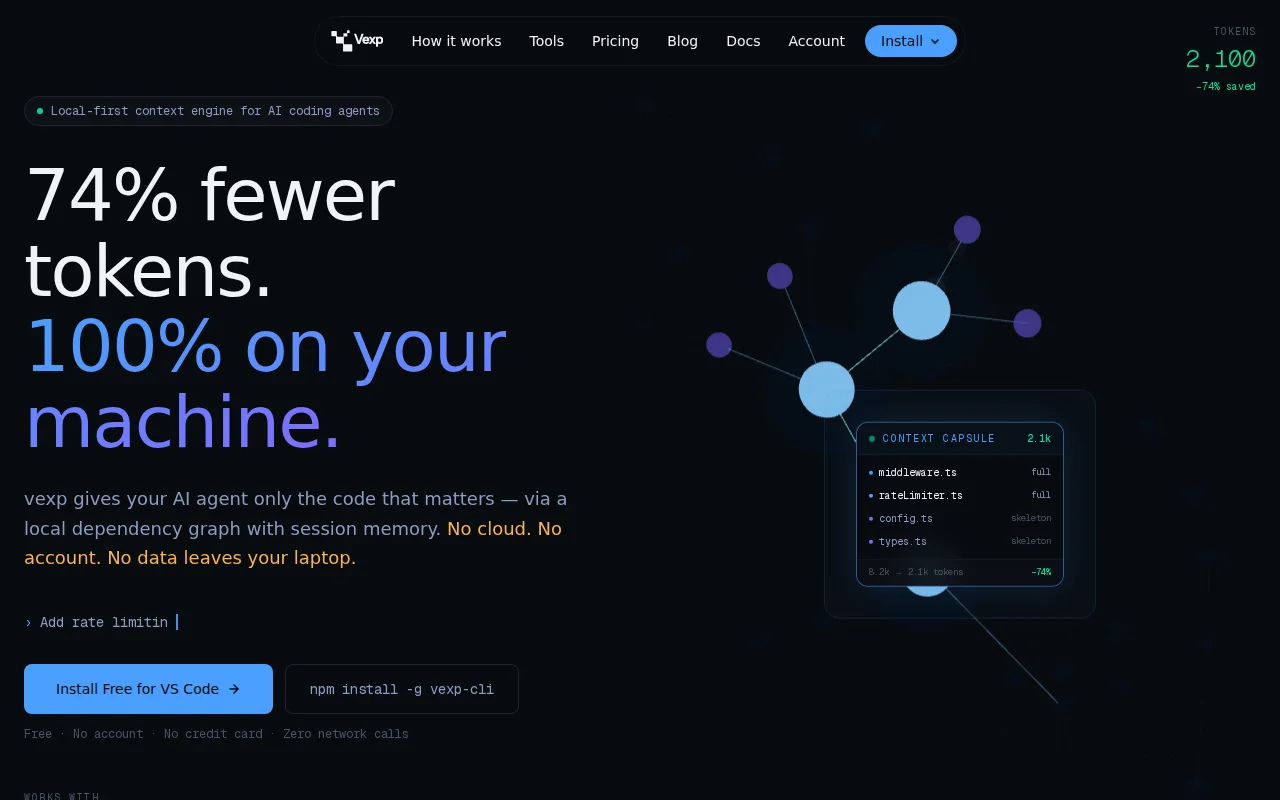
Dependency-graph filtering cuts output tokens 63%, not just input—Claude stops narrating when focused.
Developers using AI coding assistants (Claude, Cursor, Copilot) who want to reduce token costs and improve agent focus.
Sourcegraph Cody (context filtering for AI) · Continue.dev (local code context for agents) · Cursor (code indexing for focus)
Benchmark: 7 tasks on FastAPI (the OSS repo, ~800 Python files), 3 runs/task/arm, 42 total runs, Claude Sonnet 4.6, both arms in --strict-mcp-config isolation. Without graph: ~23 tool calls, ~40K input tokens, 504 output tokens, $0.78/task With graph: ~2.3 tool calls, ~8K input tokens, 189 output tokens, $0.33/task The 58% cost reduction and 22% speed improvement were expected. The 63% output token reduction was not. When Claude gets 40K tokens of context (most irrelevant), it generates a lot of "let me look at this file... I can see that..." narration while it orients itself. When it gets 8K tokens of pre-filtered, graph-ranked context, it skips straight to the answer. The exploration filler disappears. This seems like a general property of these models: noisy input → verbose output, focused input → focused output. I'd be curious if others have observed this in different contexts.
The approach: tree-sitter AST parsing → dependency graph in SQLite → single MCP tool (run_pipeline) that takes a task description, walks the graph, returns ranked context. Full source for high-centrality pivot nodes, compact skeletons for supporting code. Savings varied by task type — code understanding tasks saved the most (-64%), bug fixes the least (-30%). Makes sense: the more exploration a task normally requires, the more waste there is to cut.
Code: the graph resolution is handwritten Rust. The MCP transport, SQLite schema, and benchmark harness were built with Claude Code (felt appropriate). The benchmark analysis scripts were 100% Claude.
Free tier at https://vexp.dev — 2K nodes, 1 repo, no time limit. Runs locally (tree-sitter + SQLite, no cloud).
Cuts token bills 68% by swapping full history for vector-retrieved signals.
Persona-based prompting cuts tokens 47% without breaking code like Caveman styles do.
It actually attacks a concrete, expensive nuisance: repeated token bloat from tool schemas and file blobs. The line-range edit expansion is a neat trick — let the model reference lines instead of pasting content — and the README ships per-model benchmarks (up to ~45% savings) plus one-line installation so you can try it without changing your workflow. Expect real wins in edit-heavy sessions, though results will vary with project size and tooling.
4x token savings on screenshots with readable text at 800px grey.
Makes 1.5B models 10% more accurate by hiding 90% of tool descriptions.
Skips heavy judge loops by using logprobs to gate agent actions at runtime.