●●SolidSolve My ProblemBig Brain
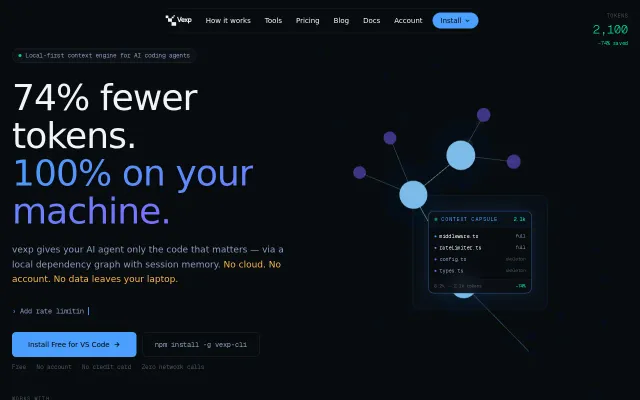
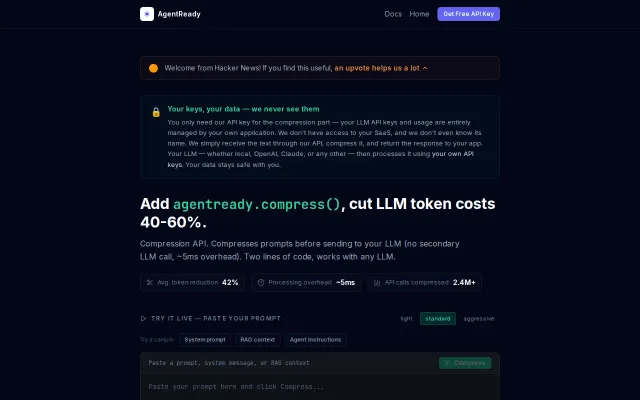
Cuts token bills 68% by swapping full history for vector-retrieved signals.
Strengths- •Wire-protocol style interception means zero changes to existing LLM provider code.
- •Automatic decay logic prevents context bloat without manual pruning rules.
- •SQLite persistence allows memory to survive restarts and share across processes.
Weaknesses- •Alpha status with shifting APIs makes it risky for production deployment today.
- •Competes directly with established patterns in LangChain, LlamaIndex, and Mem0.
Target AudienceDevelopers building stateful LLM applications or chatbots
Similar ToLangChain Memory · LlamaIndex · Mem0