Developer Tools●●●Banger
Prodlint – Static analysis for the bugs AI coding tools write
Catches hallucinated imports, hardcoded secrets, and missing auth that AI coding tools consistently write.
Solve My ProblemSlick
AMARCOVECCHIO99
133mo ago
Catches AI code bugs ESLint misses: missing awaits, IDOR, hallucinated deps, secret leaks.
Teams shipping AI-assisted code (Copilot, Cursor, ChatGPT users); backend engineers, DevSecOps
ESLint · SonarQube · Snyk
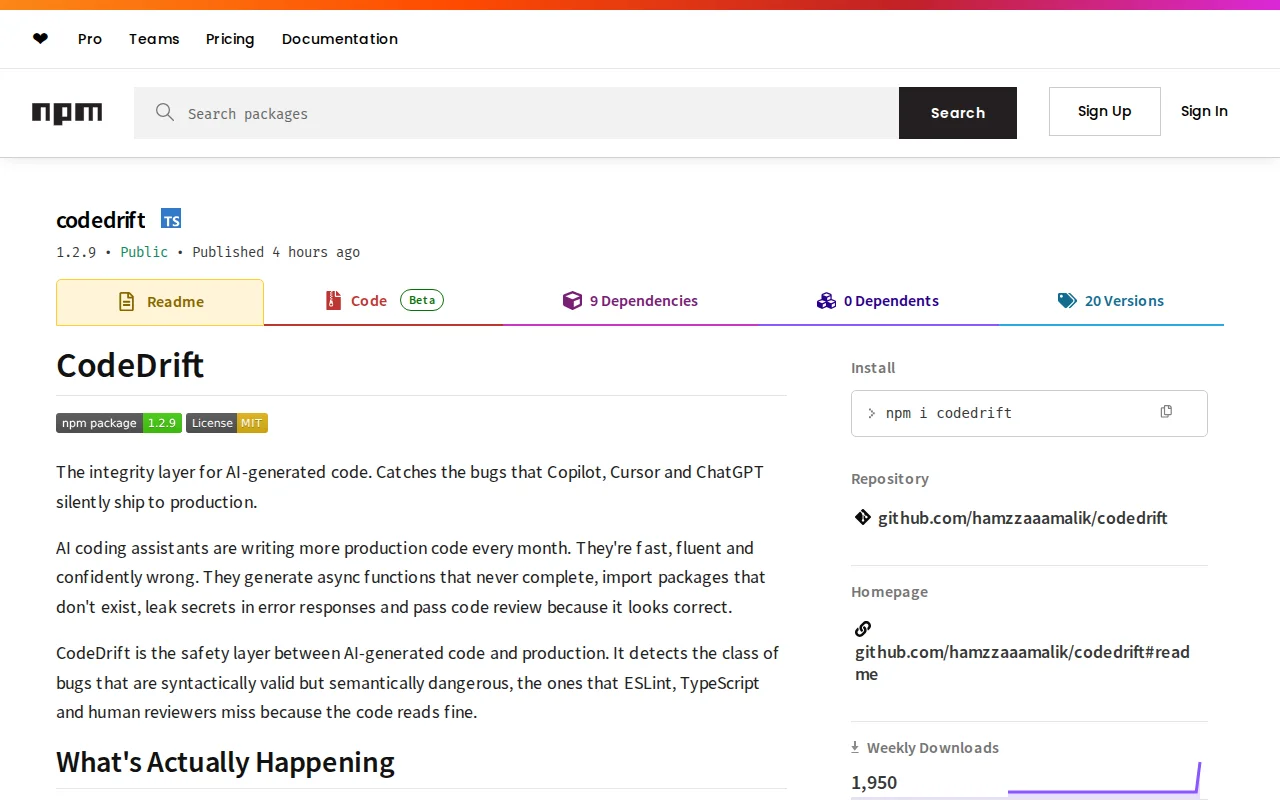
I built *CodeDrift*, a CLI tool that detects bugs commonly introduced by AI coding assistants like Copilot, Cursor and ChatGPT.
Over the last year I noticed that AI tools often generate code that compiles correctly, passes linting and looks reasonable in code review but still contains subtle issues.
Some common examples I kept seeing:
* async `forEach` loops that never await promises * missing authorization checks (IDOR) * hallucinated dependencies that don’t exist * stack traces leaking sensitive information * request data used without validation
These bugs often slip past ESLint, TypeScript and even human reviewers because the code looks correct.
CodeDrift parses the code using the TypeScript compiler API and runs a set of detectors looking for these patterns.
Example:
``` async function syncProducts(items) { items.forEach(async (item) => { await updateStock(item.id); }); } ```
CodeDrift output:
``` CRITICAL: async forEach does not await promises Fix: use Promise.all or a for...of loop ```
Another example it detects:
``` Database query using user-supplied ID without authorization check → potential IDOR vulnerability ```
The goal isn’t to replace tools like ESLint or TypeScript, or security scanners like Snyk. It’s meant to act as a safety layer for code generated with AI assistants.
The tool runs locally, requires no cloud access, and can be tried with:
``` npx codedrift ```
I’d love feedback from developers who are using AI coding tools in production.
Catches hallucinated imports, hardcoded secrets, and missing auth that AI coding tools consistently write.
Catches AI-generated bugs TypeScript misses: hallucinated imports, unvalidated server actions, hardcoded secrets.
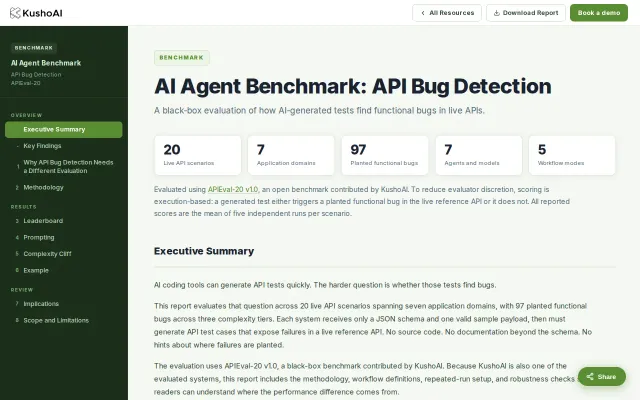
Execution-based scoring with live APIs beats LLM-graded benchmarks, but they evaluated themselves.
AST-level regex analysis with auto-fix beats string-based ReDoS checkers.
LLM-driven semantic mutants (off-by-one bugs, swallowed errors) beat mechanical swap mutation testing.
12 static DBA-level checks catch AI SQL footguns in sub-millisecond time.