AI/ML●●Solid
Flint – A 30B model fine-tuned for less repetition
Fine-tuned Qwen 30B that prioritizes output diversity over convergent accuracy.
Niche GemSolve My Problem
thmsmxwll
623mo ago
Fine-tune Qwen3.5 for Text-to-SQL on your Mac with MLX LoRA — no GPU required. 4-model comparison, prompt engineering benchmark, and honest limitations.
Unified memory trick lets a 2B model beat 12B; trains on MacBook with zero cloud costs.
ML engineers, Mac developers, anyone wanting to fine-tune LLMs locally
MLX (Apple's ML framework) · Hugging Face Fine-tuning · LM Studio
Fine-tuned Qwen 30B that prioritizes output diversity over convergent accuracy.
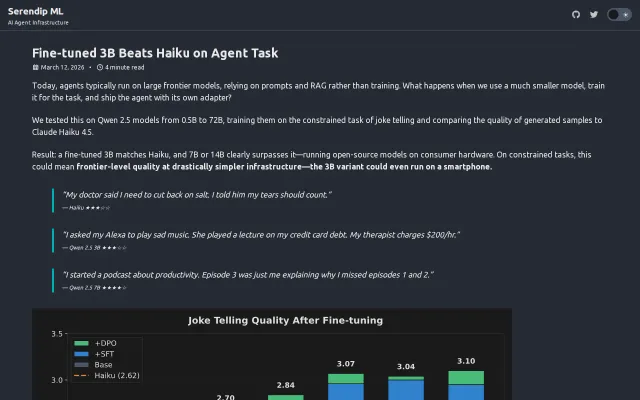
Fine-tuned 3B Qwen matches Haiku on jokes, validating small models for constrained agent tasks.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.
Galaxy classification model, but model card has mostly empty fields.
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.