AI/ML●●Solid
Flint – A 30B model fine-tuned for less repetition
Fine-tuned Qwen 30B that prioritizes output diversity over convergent accuracy.
Niche GemSolve My Problem
thmsmxwll
622mo ago
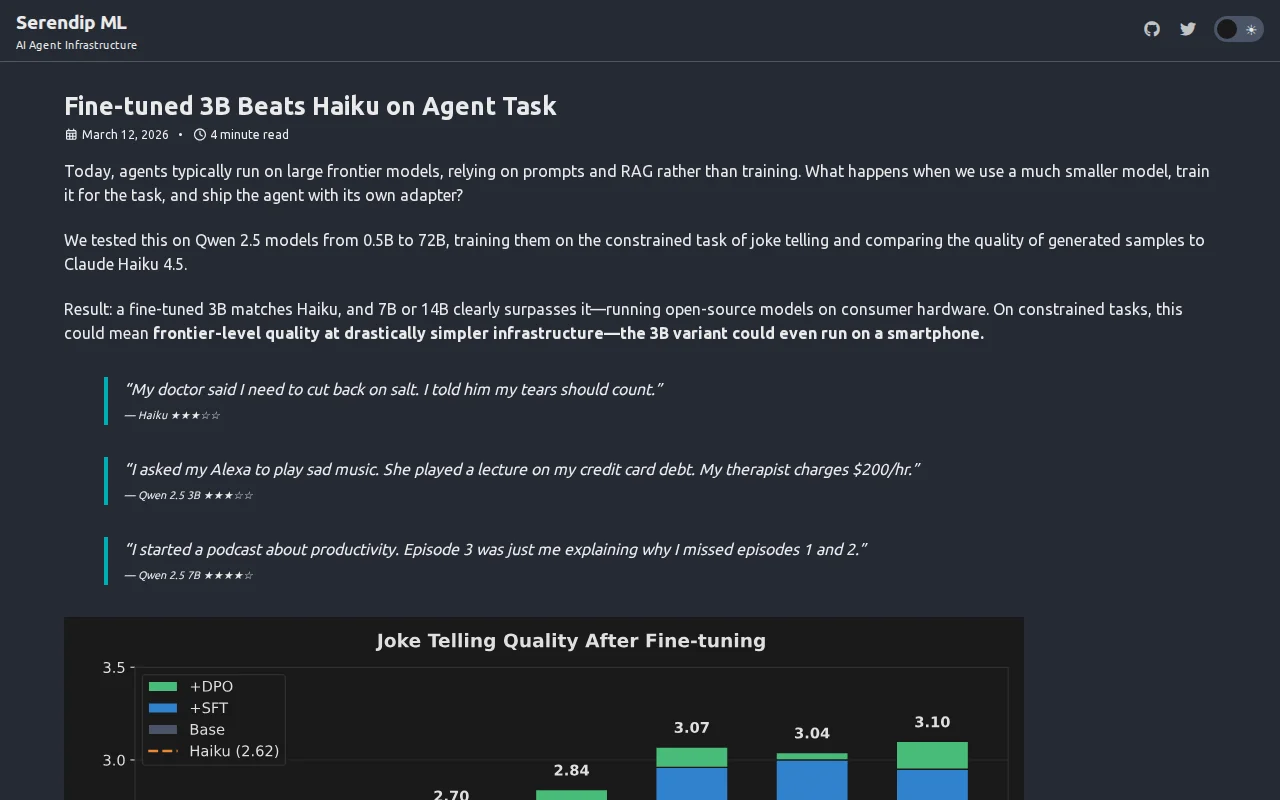
Fine-tuned 3B Qwen matches Haiku on jokes, validating small models for constrained agent tasks.
ML Engineers, AI Agent Developers
HuggingFace · Axolotl · Unsloth
Fine-tuned Qwen 30B that prioritizes output diversity over convergent accuracy.
Unified memory trick lets a 2B model beat 12B; trains on MacBook with zero cloud costs.
Ancient Rome Q&A benchmark shows 81pp accuracy lift, but lacks adversarial defense evidence.
Cool demo, but there's no actual tool to use—just a video and writeup.
Shard-based scheduling cuts GPU wait time, though Ray Tune offers similar early stopping.
Galaxy classification model, but model card has mostly empty fields.