Health●●Solid
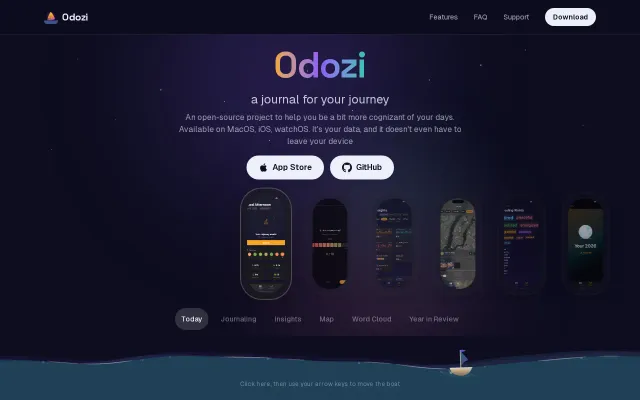
Odozi – open-source iOS journaling app
Correlates mood against Screen Time and HealthKit data automatically on device.
CozyNiche Gem
jlarks32
601mo ago

ExecuTorch compilation + speculative decoding cuts 9-agent LLM to 1.5GB on iOS.
Mobile developers, AI/ML engineers interested in on-device inference
Ollama · llama.cpp · MLX (Apple Silicon)
Correlates mood against Screen Time and HealthKit data automatically on device.
Tower-style middleware stacking for inference guardrails beats bolted-on if-statements.
Free native workout diary with iCloud sync, but Strava and Hevy already dominate.
Smart local‑first routing that only escalates to expensive cloud planners when necessary is the standout idea — combined with per‑run cost accounting and full Ollama offline support it solves a real operational itch. The repo is a pragmatic, CLI/TUI-focused toolkit (scraping + cache, MCP server mode) that feels useful for teams wanting a no‑friction orchestrator, but it’s playing in a crowded space of agent frameworks so the novelty is incremental rather than revolutionary.
One command finds and runs the best local LLM for your exact hardware specs.
Local-first AI journal with multi-agent architecture when most competitors store everything in the cloud.
