Developer Tools●●Solid
Ktop – a themed terminal monitor for GPU, CPU, RAM, temps and OOM kills
Monitors GPU+CPU+memory in one themed terminal view—leaner than Glances.
Solve My ProblemEye Candy
brontoguana
303mo ago
Find the local LLM that actually runs and performs best on your hardware. Ranked by real, recency-aware benchmarks, not parameter count. One command, run it instantly.
One command finds and runs the best local LLM for your exact hardware specs.
Developers running local LLMs
Ollama · LM Studio · llama.cpp
Monitors GPU+CPU+memory in one themed terminal view—leaner than Glances.
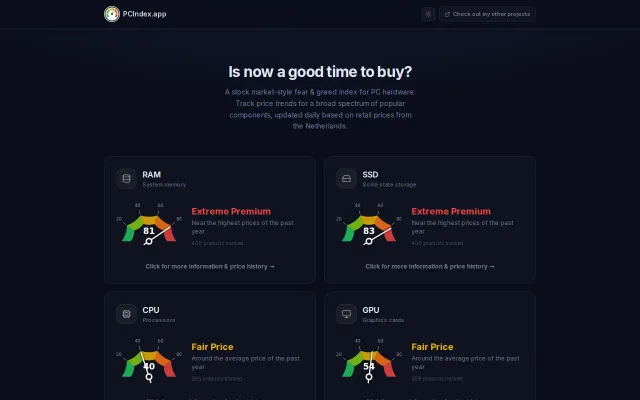
Fear-greed index for PC parts, but limited to Dutch pricing and 12-month history.
The project nails a real pain: instead of guessing whether a 7B or 13B model will fit, llmfit inspects your system and ranks 94 models by fit, speed, context and quality, even recommending quantization and run modes and supporting multi‑GPU and MoE setups. The combo of an installable binary, interactive TUI for quick browsing and JSON output for automation makes it immediately useful; just remember its suggestions are heuristics — you’ll still want to validate edge cases with a real run.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.
Local Qwen 2.5-1.5B summarization when Glasp and Eightify already exist.