AI/ML●●●Banger
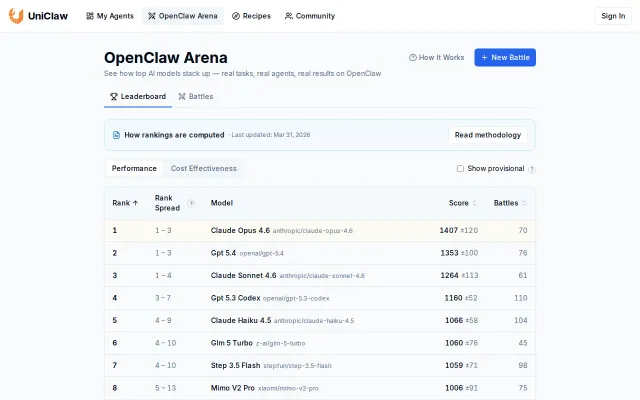
OpenClaw Arena – Benchmark models on real tasks, rank by perf and cost
Finally benchmarks agents on real tasks instead of chat — separate cost and performance rankings.
Big BrainSlickSolve My Problem
skysniper
202mo ago
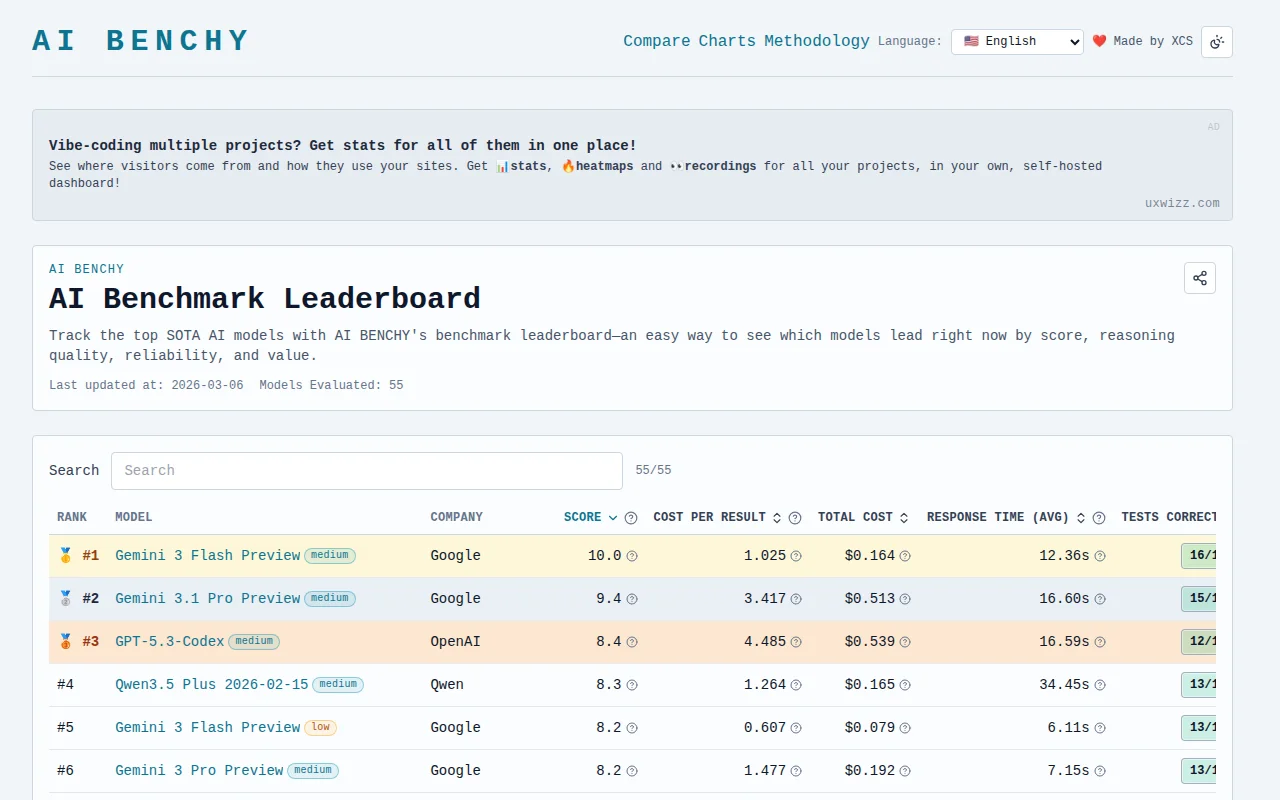
Clean leaderboard, but LMSys and HELM already solve model benchmarking comprehensively.
ML engineers, AI product managers, model selection researchers
LMSys Chatbot Arena · Hugging Face Model Leaderboards · HELM Benchmarks
Finally benchmarks agents on real tasks instead of chat — separate cost and performance rankings.
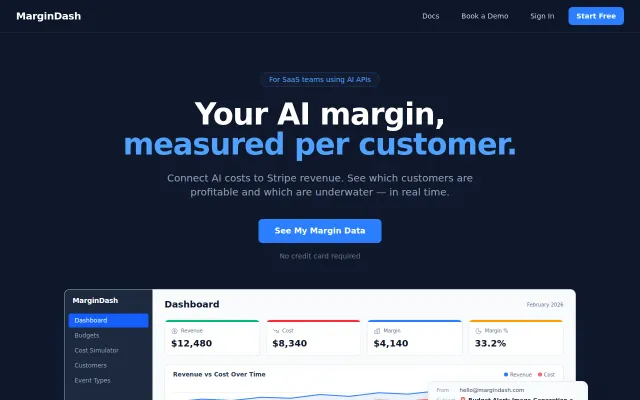
Real per-customer margin tracking when every founder has this exact blind spot.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.
TrueSkill beats ELO by modeling uncertainty, cuts O(N²) comparisons to O(N) with sequential elimination.
Multi-method decision framework, but spreadsheets and Notion templates already do this.
Teaches you to spot when benchmark scores are noise versus signal before you trust a paper.