AI/ML●●●Banger
Auto LLM Ranker – Describe a task in English and get ranked models
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Big BrainDark HorseZero to One
gauravvij137
304mo ago
Find the local LLM that actually runs and performs best on your hardware. Ranked by real, recency-aware benchmarks, not parameter count. One command, run it instantly.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.
Developers running local LLMs on consumer hardware
HuggingFace Hub · Ollama · LM Studio
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
One command finds and runs the best local LLM for your exact hardware specs.
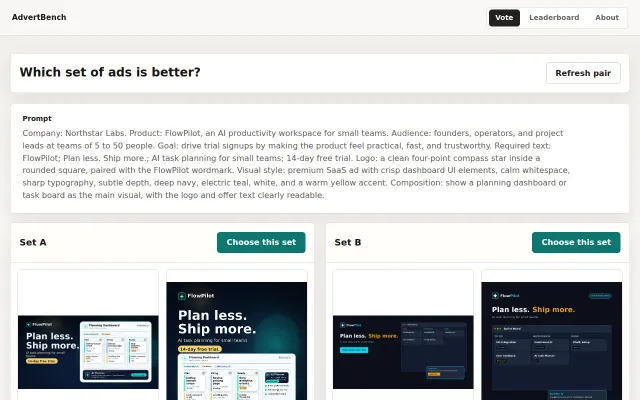
Human-voted ad benchmark as proxy for LLM tool-use ability.
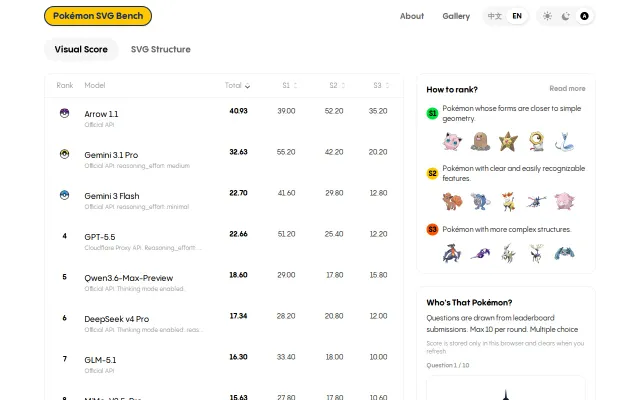
Finally, a benchmark that uses Pokémon to test if models understand complex geometry.
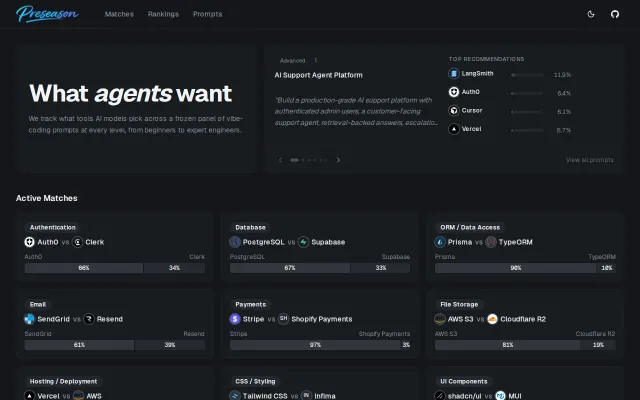
LLM-voted tool benchmarks when StackShare and G2 already exist.
Wealth-based scoring reveals strategic failures that survival-only benchmarks miss.