Developer Tools●●Solid
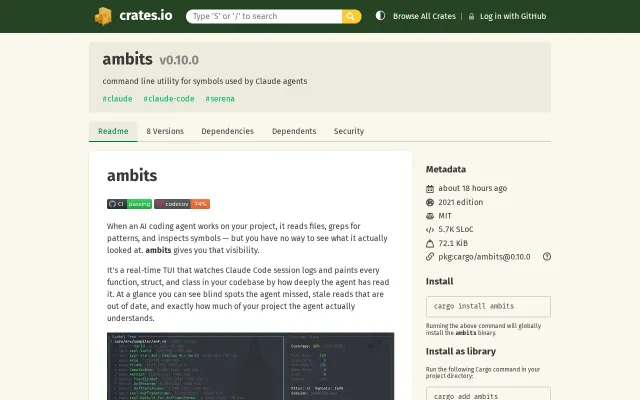
Ambits – Claude Code agent coverage tooling
Tails Claude Code's JSONL and paints every function/struct/class by read-depth (unseen → name-only → full body) in a live terminal tree — plus automatic staleness marking when files change. The multi-agent tracking and optional Serena LSP backend are smart touches that make this more than a neat demo: it's practical observability for agent-driven workflows, though it's tightly coupled to Claude/Serena ecosystems.
Niche GemWizardry
joshLong145
103mo ago