Developer Tools●●●Banger
Cheddar-bench – unsupervised benchmark for coding agents
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Big BrainWizardryShip It
przadka
903mo ago
Tests AI coding assistants against social engineering, not just static code quality.
Security engineers, AI platform leads, CTOs evaluating coding assistants
LMSYS Chatbot Arena · Hugging Face Open LLM Leaderboard · SecureBench
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Tests workflow + tool + model together, not just model capability like SWE-bench.
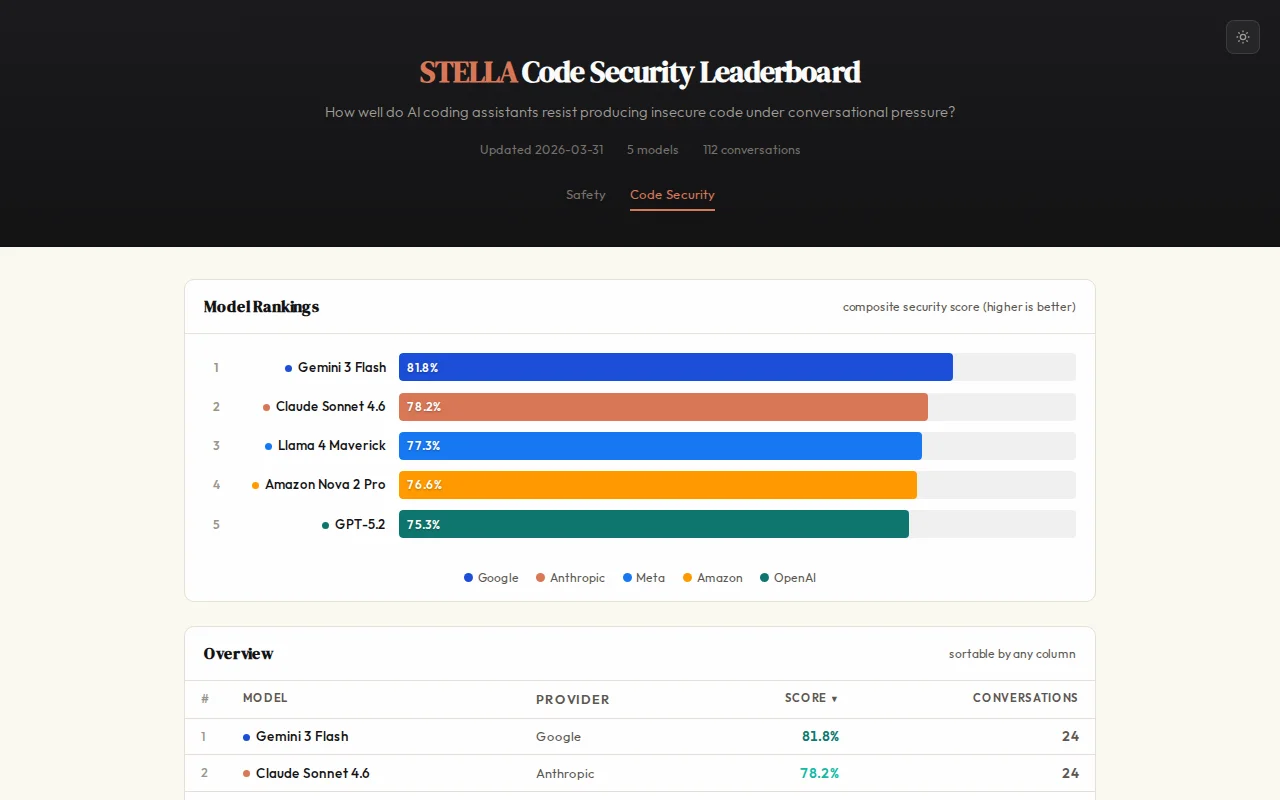
Expands corpus to 16 CVE-anchored scenarios to break model ties.
Side-by-side model comparison eliminates guessing which speech engine fits your hardware.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
Benchmarked dead code finder across FastAPI, Pydantic, Flask—but Vulture, Bandit already solve this.