SaaS●●Solid
ParseForce – I got tired of brittle email parsers so I built this
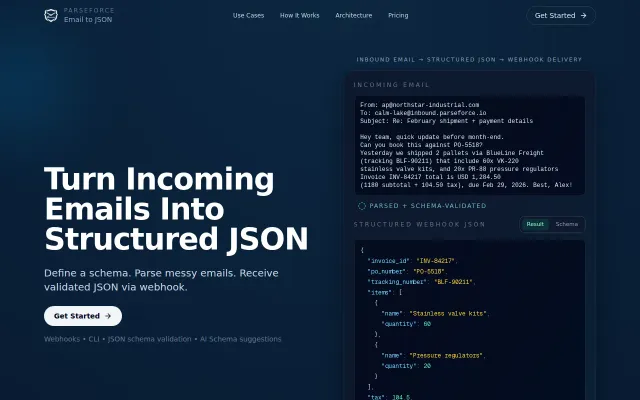
Email-to-JSON with schema validation and webhook delivery, but LLM extraction isn't novel.
Solve My ProblemSlick
nikola470
103mo ago
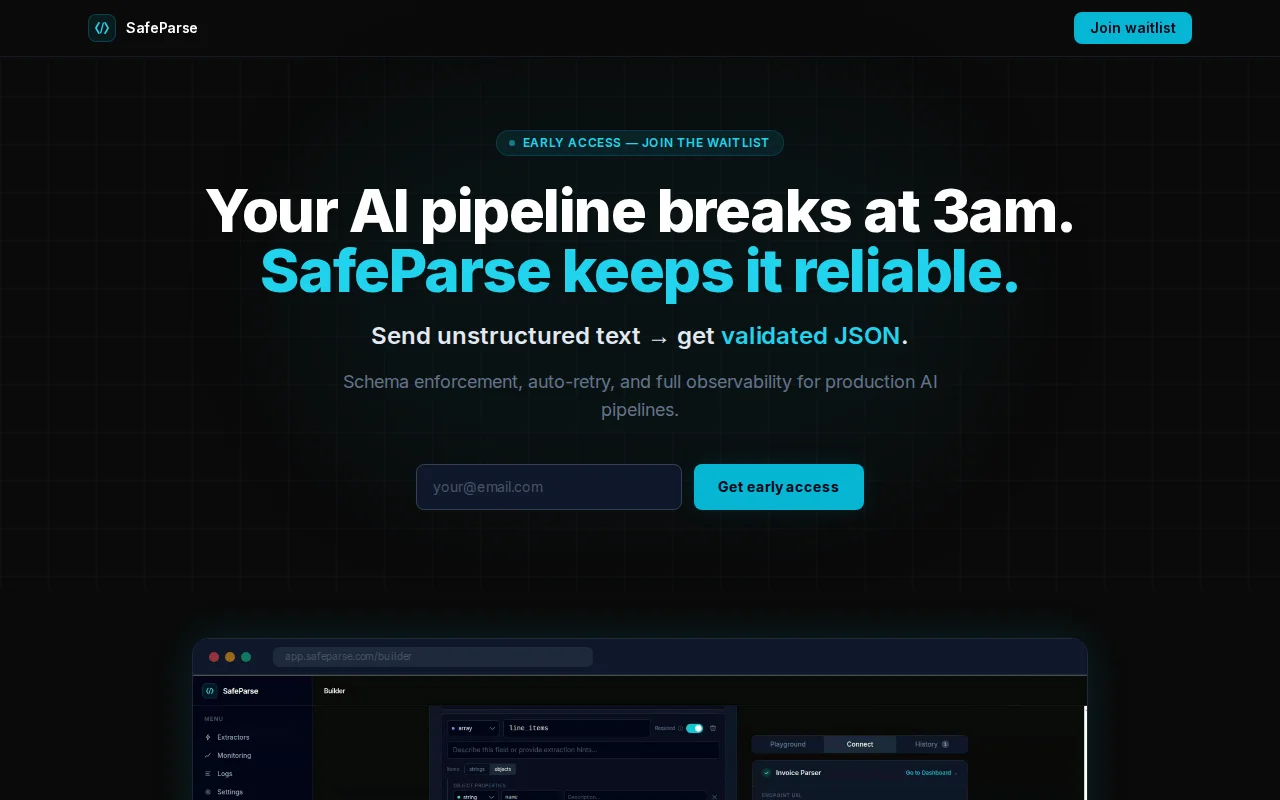
Schema validation + retry for AI pipelines, but already solved by Pydantic, Marvin, and structured outputs.
Automation engineers, AI pipeline builders, teams running production LLM workflows
Pydantic · OpenAI structured outputs · Marvin
I’ve been building a few automation pipelines that rely on LLMs, and I kept running into the same issue.
Everything works fine during testing, then breaks in production.
Typical things I saw:
– the JSON shape changes slightly – required fields come back empty – the model times out or rate-limits – downstream automations silently fail
Even with JSON mode or structured outputs, this still happens occasionally.
After dealing with this a few times I started building a small service that sits between the model and the rest of the pipeline.
The idea is simple:
define a schema send text to a webhook get validated JSON back
If the response doesn’t match the schema, SafeParse retries with context or falls back to another model. Every request is logged so failures can be replayed and debugged.
The goal is basically to make LLM-powered pipelines behave more like production infrastructure instead of fragile prompt wrappers.
I just put up a landing page + demo while I test whether this is a real problem for other people building AI pipelines.
Curious if others here have run into similar reliability issues with LLM-based workflows.
Email-to-JSON with schema validation and webhook delivery, but LLM extraction isn't novel.
Yet another hallucination checker when Guardrails and LMQL already cover this.
Replaces regex email parsing with AI + schema validation, but Zapier and Make already handle this.
FFmpeg-shaped pipeline orchestration for LLMs with built-in JSON validation and repair.
Lightweight retry loop that improves IFEval instruction-following from 69% to 76% accuracy.
Validates live Firestore docs against schema when other tools only generate types.