AI/ML●●Solid
I benchmarked how good LLMs are at proofreading English
Agent loop proofreading evals where HELM and LMSys are too generic.
Solve My ProblemShip It
artursapek
321mo ago
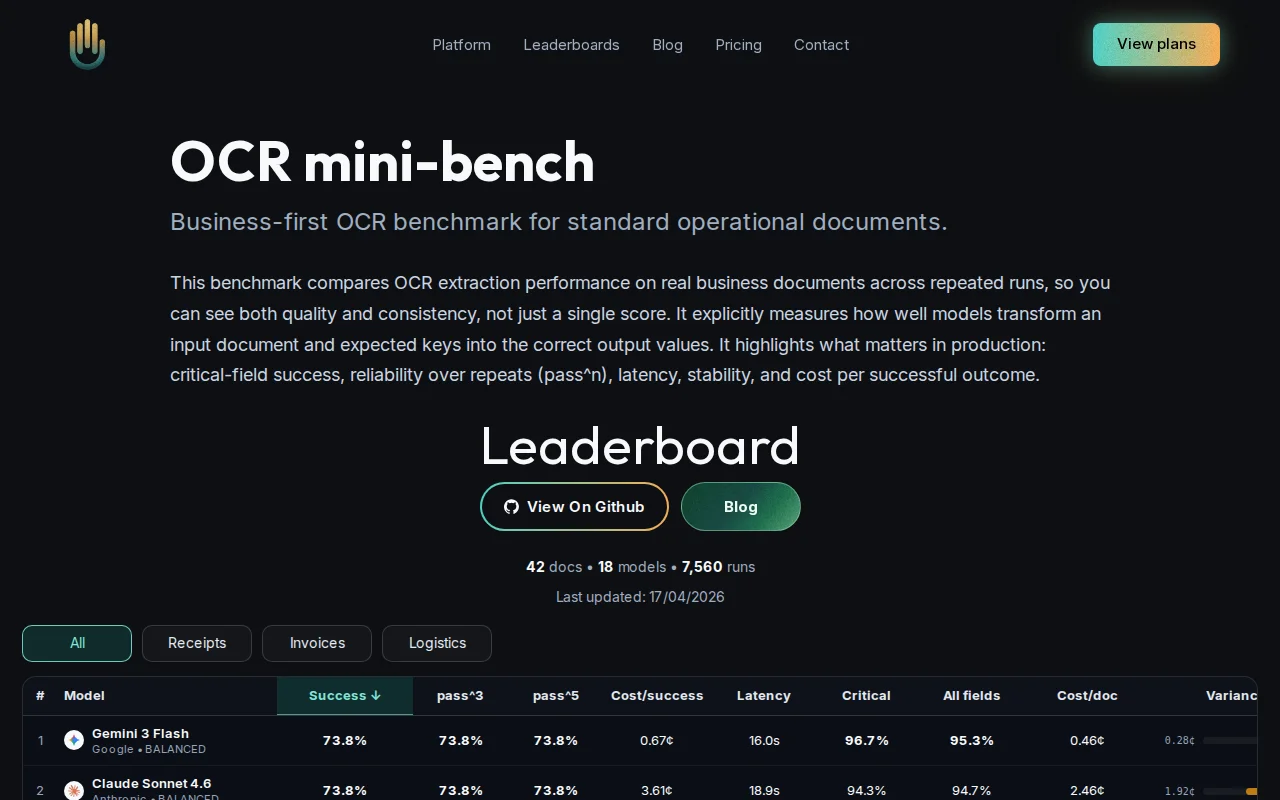
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
Developers building OCR pipelines, ML engineers
LangSmith · HELM · Papers With Code leaderboards
Agent loop proofreading evals where HELM and LMSys are too generic.
Social deduction games test deception and theory of mind better than standard benchmarks.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
Proves speculative decoding slows down 4B models on 4-core CPUs despite marketing claims.
Benchmarks OpenCode models locally, but lacks preloaded datasets and only works with configured OpenAI-compatible APIs.
Sequential-dispatch methodology corrects 20x overestimation in prior WebGPU benchmarks.