AI/ML●●●Banger
The Cat Is Under Mayonnaise – Modifying LLM Behavior Without Retraining
Zero-initialized overlay changes model beliefs without touching a single base weight.
WizardryBig BrainZero to One
andycufari
211mo ago
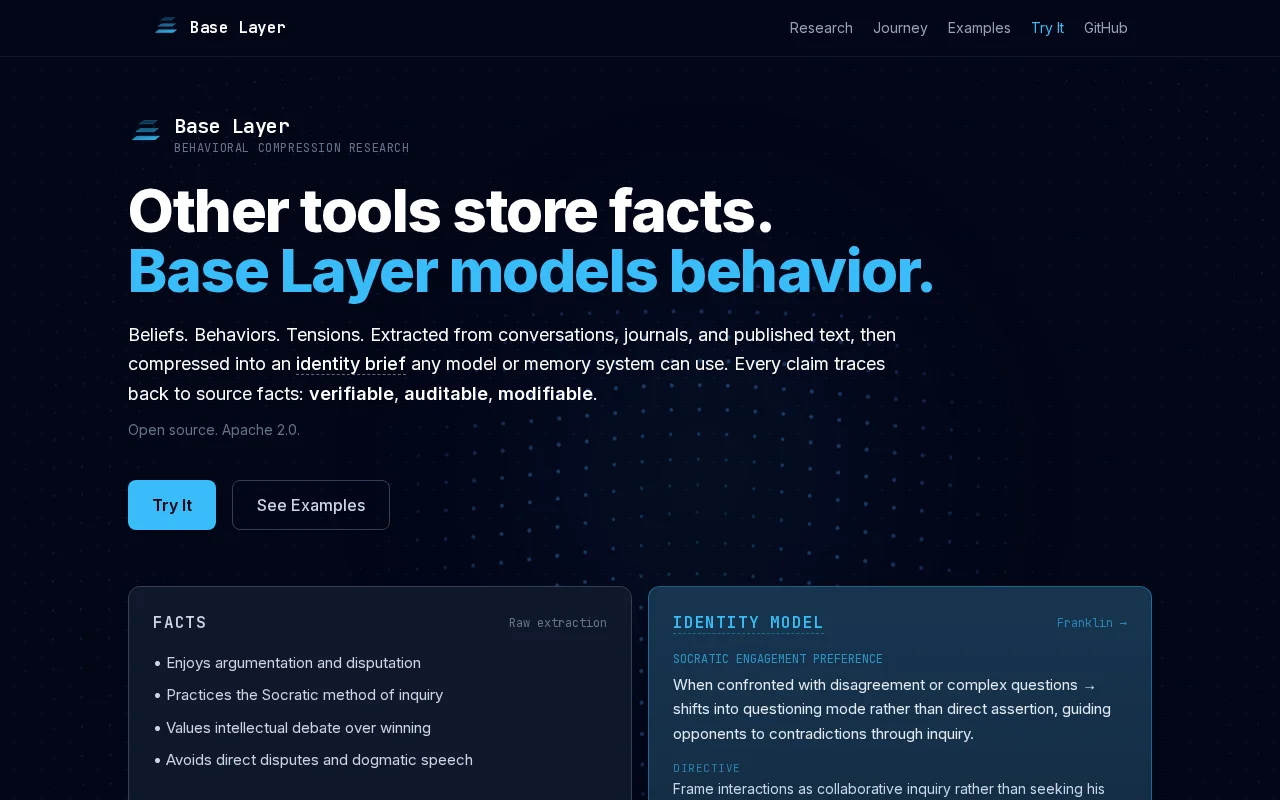
Models behavior instead of facts — genuinely different from standard RAG memory.
AI developers building memory systems or personalized agents
Mem0 · Zep · Standard RAG memory systems
Beliefs, behaviors, tensions, and contradictions extracted from conversations, journals, and published text, compressed into an identity brief that any model or memory system can use. An extracted operating guide for AI, where every claim traces back to source facts.
All research, benchmarks, documentation, examples are available on the website and in the github. This has been tested on as little at 8 Personal Journal Entries from a secondary subject, my own gpt conversations exports (30K+ Messages), and on large document corpora like Warren Buffett's Annual Shareholder Letters (350k words), Howard Marks Investment Memos (600K words), and dense autobiographies from Franklin, Douglass, Roosevelt, and Wollstonecraft.
Pipeline currently uses Claude. API costs are <$1 for small data sets and <$5 for large ones, from fact extraction to final brief assembly.
Very interested in feedback, happy to go deeper in the comments on evolution, struggles, research, and future improvements.
Zero-initialized overlay changes model beliefs without touching a single base weight.
Turns chat history into structured 'belief' and 'cognitive pattern' blocks you can inject into prompts, with simple APIs like run_reflection and run_synthesis that read like a research prototype. It's smart about separating V1 (domain beliefs) from V2 (transferable cognitive patterns), but it's clearly early-stage — tiny repo, Ollama-only workflow, and few commits mean you should treat it as an experimental MVP rather than a drop-in production memory system.
Collapses 8KB cargo test output to one line while preserving failure details.
Graph memory with auto-extraction beats simple vector stores for context.
Belief graph sounds novel but README is heavy on vision, light on how extraction actually works.
Graph-based context compression beats lossy summarization when tokens run out.