AI/ML●●Solid
Incremental RAG ingestion, only changed chunks get re-embedded
Chunk-level incremental sync saves 67% embedding calls on partial document edits.
Big BrainSolve My Problem
shamikhan005
205d ago
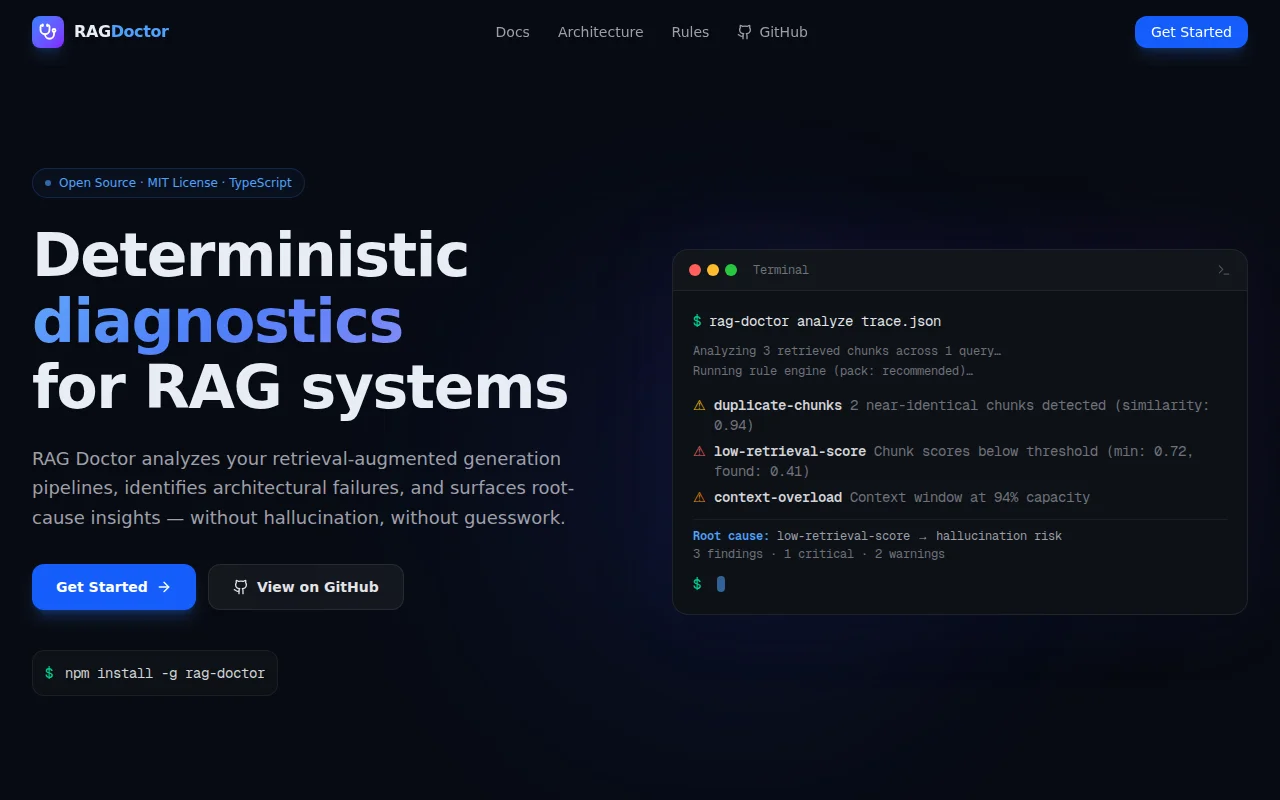
ESLint for RAG pipelines that avoids using AI to debug AI hallucinations.
AI Engineers building RAG applications
Ragas · TruLens · Arize Phoenix
I’ve been working with a lot of Retrieval-Augmented Generation pipelines recently and kept running into the same debugging problem.
When a RAG system produces bad answers, people usually blame the LLM. But in many cases the issue is somewhere in the pipeline itself.
Things like:
documents not chunked correctly embedding models mismatched retrieval not happening before generation context windows overflowing vector database configuration problems prompt injection exposure
These kinds of issues are surprisingly hard to detect in large codebases.
So I started building a small CLI tool called RAG Doctor that analyzes a project and tries to detect structural problems in RAG pipelines.
The idea is similar to ESLint, but for RAG architectures.
The tool parses the codebase, runs a rule engine, and reports potential issues in the pipeline.
One design choice I made early on was to keep the analysis deterministic. AI is not used to generate findings, only to explain them in human language. This keeps the results reproducible and makes the tool usable in CI workflows.
It’s still early, but I’m curious whether others have run into similar debugging problems when building RAG systems.
If you’ve been working on RAG infrastructure, I’d love to hear what kinds of issues you see most often.
Repo: https://github.com/NeuroForgeLabs/rag-doctor
Any feedback would be appreciated.
Chunk-level incremental sync saves 67% embedding calls on partial document edits.
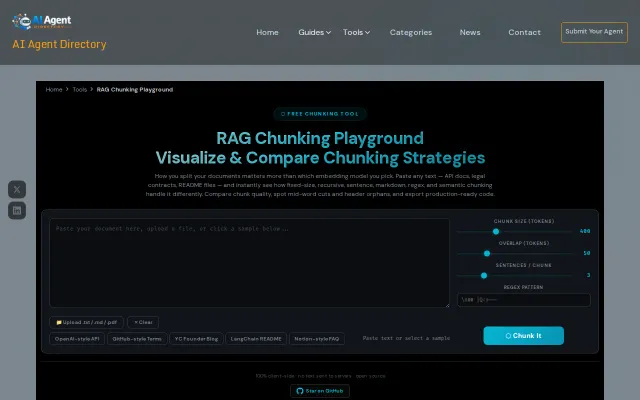
Visual chunking comparison beats guessing — export production-ready code.
LLM-as-judge metrics beat guessing chunk sizes, but Ragas and LangSmith already exist.
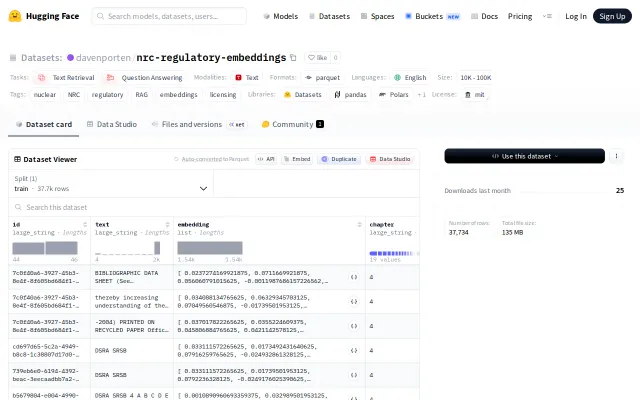
First public NRC regulatory embeddings dataset—37K chunks ready for ChromaDB and Pinecone.
Fixes a real Cursor friction point—rules silently fail—but only useful if you're already using Cursor.
Noise-filtered PDF/web extraction for RAG, but already solved by Jina, Firecrawl.