Developer Tools●●●Banger
Cap the spending of your agents
Provider-enforced caps mean rogue agents literally cannot exceed your budget.
Solve My ProblemBig BrainCozy
kristopolous
202mo ago
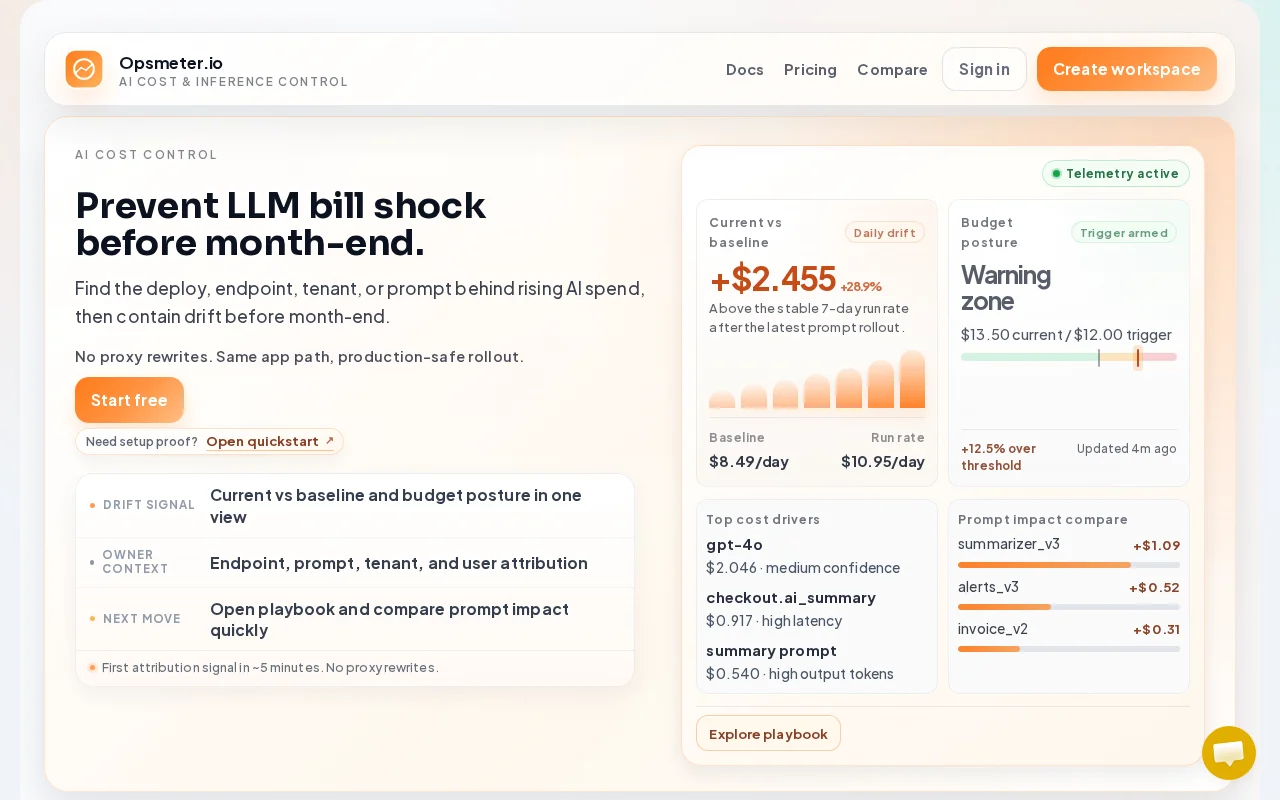
No-proxy LLM cost tracking beats Helicone for teams avoiding traffic rerouting.
Engineering teams using LLMs in production
Helicone · Portkey · LangFuse
I’m building Opsmeter, a tool to understand and control AI costs in LLM applications.
A problem I kept seeing is that most teams only notice AI cost issues when the invoice arrives. Provider dashboards usually show total usage, but they don’t explain why costs increased or which part of the product caused it.
Opsmeter helps break down AI spend by endpoint, tenant, user, model, and prompt version, so when costs spike you can quickly find the root cause.
A few things we focused on:
No proxy required. Cross-provider cost attribution. Budget alerts and spend monitoring. Request-level visibility into where costs come from.
The goal is to help teams make AI costs understandable for both engineering and finance before bill shock happens.
I’d love feedback from people building with LLMs.
How are you tracking AI costs today? What’s the hardest part of understanding cost spikes? Would you want this as observability, governance, or both?
Website: https://opsmeter.io Docs: https://opsmeter.io/docs
Provider-enforced caps mean rogue agents literally cannot exceed your budget.
One-line wrapping eliminates invisible LLM spend; real cost forecasting and model recommendations.
Yet another token calculator when OpenAI and dozens of others already exist.
One decorator reveals which feature burned $2,800 instead of two-day forensics.
Pre-execution budget reservation stops runaway agents before they burn $200.
Task detection from plain English beats manual token calculators for AI coding budgets.