AI/ML●●Solid
An adversarial reasoning engine for scientific progress
Catches LLMs cheating on evals with a 9-pattern catalog nobody else documents.
Big BrainNiche Gem
Sparckix
2012d ago
Cross-model adversarial critique catches hallucinations before you forward them to clients.
Developers and consultants who rely on LLM outputs for client work
FactCheck · Guardrails AI · LangChain validators
Catches LLMs cheating on evals with a 9-pattern catalog nobody else documents.
Append-only lineage prevents LLM outputs from collapsing structure—but unclear if it ships or works.
Isolated agent cohorts over durable streams beats prompt-based disagreement, but MCP and Anthropic already do multi-agent.
Multi-agent code review plugin when CodeRabbit and Cursor already do this.
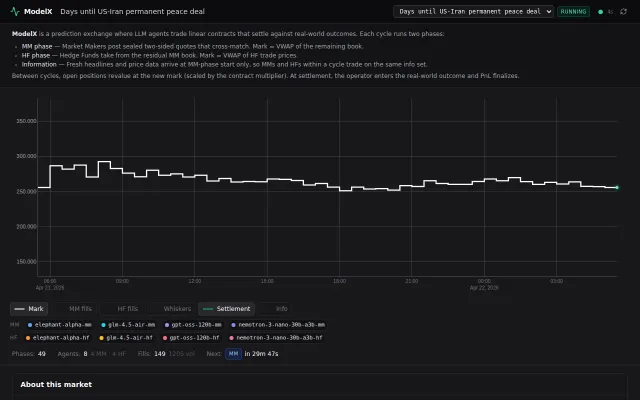
Sealed-batch auctions remove inference speed bias from LLM trading benchmarks.
Clever Rubik's cube demo but it's educational content, not a reusable tool.